重构网络 SDN架构与实现
前言
本文为学习《重构网络 SDN架构与实现》这本书后的相关笔记与摘要。
序言
SDN(Software-Defined Networking,软件定义网络)起源于斯坦福大学NickMcKeown教授的CleanSlate项目,其目标是重新定义网络体系结构(ReinventtheIntenet),诞生至今已经快十年。作一种新的网络体系结构,SDN已经揩起了一场网络变革的技术浪潮,对网络学术界和工业界的发展都产生了巨大的冲击:OpenFlow的论文至今已经被引用4951次;开源SDN控制器平台OpenDaylight已经布了5个版本,拥有超过600多名开发者,完成了超过30000多次代码更新;开源社区OSS(OpenSourceSDN)也已经发布了20多个来自开发者的开源SDN项目;传统网络设备厂商和运营商都在面向SDN重建自己的产品体系,大多数SDN初创公司都在各自领域交付成熟的产品方案。而作为学习者的我们,也需要做好准备,迎接这场技术变革。
重塑网络
SDN是什么
SDN的定义是:“SDN是一种逻辑集中控制的新网络架构,其关键属性包括:数据平面和控制平面分离;控制平面和数据平面之间有统一的开放接口OpenFlow。”在ONRC的定义中,SDN的特征表现为数据平面和控制平面分离,拥有逻辑集中式的控制平面,并通过统一而开放的南向接口来实现对网络的控制。ONRC强调了“数控分离”,逻辑集中式控制和统一、开放的接口。
SDN主要有如下三个特征:
-
网络开放可编程:SDN建立了新的网络抽象模型,为用户提供了一套完整的通用API,使用户可以在控制器上编程实现对网络的配置、控制和管理,从而加快网络业务部署的进程。
-
控制平面与数据平面的分离:此处的分离是指控制平面与数据平面的解耦合。控制平面和数据平面之间不再相互依赖,两者可以独立完成体系结构的演进,类似于计算机工业的Wintel模式,双方只需要遵循统一的开放接口进行通信即可。控制平面与数据平面的分离是SDN架构区别于传统网络体系结构的重要标志,是网络获得更多可编程能力的架构基础。
-
逻辑上的集中控制:主要是指对分布式网络状态的集中统一管理。在SDN架构中,控制器会担负起收集和管理所有网络状态信息的重任。逻辑集中控制为软件编程定义网络功能提供了架构基础,也为网络自动化管理提供了可能。
因此,只要符合以上三个特征的网络都可以称之为软件定义网络。在这三个特征中,控制平面和数据平面分离为逻辑集中控制创造了条件,逻辑集中控制为开放可编程控制提供了架构基础,而网络开放可编程才是SDN的核心特征。
一般来说,SDN网络体系结构主要包括 SDN网络应用 、 北向接口 、 SDN控制器 、 南向接口 和 SDN数据平面 共五部分。
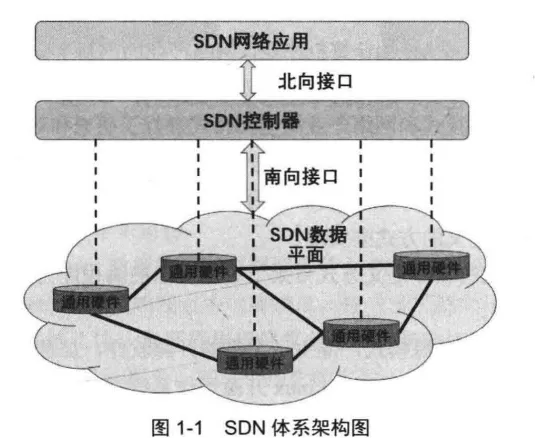
SDN网络应用层实现了对应的网络功能应用。这些应用程序通过调用SDN控制器的北向接口,实现对网络数据平面设备的配置、管理和控制。
北向接口是SDN控制器与网络应用之间的开放接口,它将数据平面资源和状态信息抽象成统一的开放编程接口。
SDN控制器是SDN的大脑,也称作网络操作系统。控制器不仅要通过北向接口给上层网络应用提供不同层次的可编程能力,还要通过南向接口对SDN数据平面进行统一配置、管理和控制。
南向接口是SDN控制器与数据平面之间的开放接口。SDMN控制器通过南向接口对数据平面进行编程控制,实现数据平面的转发等网络行为。
SDN数据平面包括基于软件实现的和基于硬件实现的数据平面设备。数据平面设备通过南向接口接收来自控制器的指令,并按照这些指令完成特定的网络数据处理。同时,SDN数据平面设备也可以通过南向接口给控制器反馈网络配置和运行时的状态信息。
为什么需要SDN
在SDN架构中,网络的控制平面与数据平面相分离,数据平面将变得更加通用化,变得与计算机通用硬件底层类似,不再需要具体实现各种网络协议的控制逻辑,而只需要接收控制平面的操作指令并执行即可。网络设备的控制逻辑转而由软件实现的SDN控制器和SDN应用来定义,从而实现网络功能的软件定义化。随着开源SDN控制器和开源SDN开放接口的出现,网络体系结构也拥有了通用底层硬件、支持软件定义和开源模式三个要素。
而对于网络而言,现有的分层协议可以看作一种数据平面抽象模型,但是控制平面依然只是网络功能和网络协议的堆砌,缺少合适的抽象模型。所以,网络需要建立控制平面的抽象模型。
而在SDN架构中,SDN控制平面、数据平面通用抽象模型和全局网络状态视图三种抽象模型实现了包括控制平面抽象在内的网络抽象架构。SDN控制平面抽象模型支持用户在控制平面上进行编程去控制网络,而无须关心数据平面的实现细节;SDN数据平面通用抽象模型将不同协议的匹配表整合起来,形成多字段匹配表,解决了网络协议堆砌问题;集中式的SDN控制平面也可以统计网络状态信息,提供描述网络状态的抽象模型。因此,通过进一步的抽象,SDN可以使网络从“管理复杂性”阶段到“提取简单性”阶段转变,满足网络用户对易用性的需求,使网络管理更加简单,更加自动化和智能。这也是为什么需要SDN的原因之一。
SDN南向协议
SDN南向协议简介
在SDN架构中,网络的控制平面和数据平面相互分离,并通过南向协议进行通信,使得逻辑集中的控制器可以对分布式的数据平面进行编程控制。南向协议提供的可编程能力是当下SDN可编程能力的决定因素,所以南向协议是SDN最核心、最重要的接口标准之一。
SDN南向协议尝试为网络数据平面提供统一的、开放的和具有更多编程能力的接口,使得控制器可以基于这些接口对数据平面设备进行编程控制,指导网络流量的转发等行为。根据南向协议提供的可编程能力可以将SDN南向协议分为狭义SDN南向协议和广义SDN南向协议两大类。
狭义的SDN南向协议
狭义的SDN南向协议具有对数据平面编程的能力,可以指导数据平面设备的转发操作等网络行为,典型的SDN南向协议有OpenFlow协议等。OpenFlow协议可以通过下发流表项来对数据平面设备的网络数据处理逻辑进行编程,从而实现可编程定义的网络。所以狭义SDN南向协议的关键在于是否具有确切的数据平面可编程能力。
POF协议/架构和P4语言/协议也可以归类到SDN狭义南向协议的范畴,但由于这两者比SDN南向协议有更通用的抽象能力,其能力范围已经超越了狭义SDN南向协议的定义,所以并不能简单地归类到狭义SDN南向协议。
POF不仅可以实现软件定义的网络数据处理,而且还可以实现软件定义的网络协议解析。即POF可以实现对数据平面协议解析过程和数据处理过程两部分的软件定义,拥有数据平面编程能力,支持协议无关的转发,是完全可编程的南向协议。而OpenFlow仅支持通过软件定义网络数据的处理逻辑,无法对数据平面数据解析逻辑进行编程,所以当需要支持新网络协议时,就暴露出抽象能力不足的缺点。
P4也是一个可对数据解析逻辑和数据处理逻辑编程的语言或者框架。P4不仅是一个SDN南向协议,还是一门网络编程语言,即可以通过P4协议对底层交换机进行编程控制。因为P4的范围超越了纯粹SDN南向协议,包涵了网络编程语言的概念。
本质上,POF和P4更准确的归类应该是完全可编程的通用抽象模型,因为它们同时支持数据平面和控制平面的软件定义。
广义的SDN南向协议
广义的SDN南向协议主要分为三种类型。第一种是仅具有对数据平面配置能力的南向协议;第二种是应用于广义SDN,具有部分可编程能力的协议;第三种是本来就存在,其应用范围很广,不限于应用在SDN控制平面和数据平面之间传输控制信令的协议。
第一种网络设备配置类型协议的代表有OF-Config、OVSDB和NETCONF等协议。目前,这些南向协议已经被OpenDaylight等许多SDN控制器支持。然而,它们只是能对网络设备的资源进行配置,无法指导数据交换。不过,这些协议应用于SDN控制器和数据交换设备之间,所以也属于SDN南向协议范畴。配置型南向协议是OpenFlow等狭义SDN南向协议的补充,完成对设备资源的配置。
第二种广义的SDN南向协议是应用于广义SDN架构的南向协议,比如应用于ACI架构的OpFlex协议。在ACI架构中,数据平面设备依然保留了很多控制逻辑,甚至更智能,依然负责数据转发等功能,但支持远程控制器通过OpFlex协议来下发策略,指导数据转发设备去实现某一个网络策略。然而,OpFlex是声明式控制(DeclarativeControl)的协议,其只传输网络策略,并不规定实现网络策略的具体方式,具体实现方式由底层设备实现。在这种情况下,OpFlex具有可编程能力,但是仅拥有很弱的编程能力,无法做到更细致粒度的调度和控制。
第三种广义SDN南向协议是可应用于SDN的南向协议,其代表有PCEP和XMPP。两者本质上都具有可编程能力,但均不是专门为SDN而设计的,而是本来就存在,只是被应用在SDN框架中。PCEP最初被广泛用于TE领域,在SDN出现之后,经常被应用在SDN框架中。而XMPP可被应用于许多场景,如网络聊天等,其被应用于SDN只是因为其功能适合携带南向数据。
狭义SDN南向协议
OpenFlow介绍
OpenFlow是第一个SDN控制平面和数据平面之间交互的通信接口,也是目前最流行的SDN南向协议。
在OpenFlow1.0版本规范中定义了OpenFlow交换机,流表和OpenFlow通道。相比1.0版本,OpenFlow1.3版本新增了组表和Meter表两种新表。

OpenFlow交换机
OpenFlow交换机可以分成流表和安全通道两部分。顾名思义,流表就是用于存放流表项的表。
在OpenFlow协议规范中,控制器可以给交换机下发流表项来指导交换机处理匹配流表项的数据包。安全通道是用于和控制器通信的安全连接。安全通道可以直接建立在TCP之上,也可以基于TLS加密之后的Socket建立。
在OpenFlow交换机和控制器连接的初始化阶段,需要将自身支持的特性和端口描述等信息上报给控制器。当数据包从入端口进入交换机且匹配流表项失败时,就会将数据包放在Packet-in报文中上报到控制器。控制器接收到Packet-in报文之后,可以选择下发流表项和下发Packet-out报文等方式来告知交换机如何处理这个数据流。因此,在OpenFlow的协议架构中,交换机成为了策略的执行者,而网络的相关策略需要由控制器下发。随着OpenFlow协议的发展,OpenFlow又新增了组表和Meter表两种表,所以支持高版本协议的OpenFlow交换机中存在流表、组表和Meter表三种表。
目前,支持OpenFlow协议的设备分为OpenFlow交换机和支持OpenFlow协议的交换机两种。前者只有OpenFlow协议栈,而后者拥有OpenFlow协议栈和传统的网络协议栈,可以支持两种运行模式。
OpenFlow表
流表
流表(Flow Table)是交换机用于存储流表项的表。其结构示意图如下图所示。在OpenFlow1.0版本中仅有一张流表,即单流表。由于单流表可以支持的程序逻辑太简单,无法满足复杂的业务逻辑,所以在OpenFlow1.1版本规范中就提出了多级流表的概念。
多级流表将数据包的处理逻辑划分为多个子逻辑,并由多张流表分别来匹配和处理,从而使得数据包的处理变成了一条流水线。多级流表的设计使得流表项聚合成为可能,节省了流表空间,也提高了编程处理逻辑的灵活性。
每一条流表项由匹配域、指令集和计数器三个主要部分及其他部分组成。其中匹配域用于区分不同的数据流。网络数据包进入交换机之后会匹配流表中的流表项,匹配到同一条流表的数据包被称为数据流,即DataFlow,简称Flow。数据包匹配成功之后,需要执行相关的指令,用于完成数据的处理。计数器部分则记录了匹配该流表的数据包的数目和字节数等相关数目。

组表
组表(Group Table)是OpenFlow1.1版本规范中提出的,其结构示意图如下图所示,顾名思义,其用于定义一组动作,且这组动作可被多条流表项共同使用,从而实现组播、负载均衡、容灾备份和精合等功能。
组表的存在降低了流表项的逻辑复杂度,也减少了流表存储空间。

Meter表
Meter表(Meter Table)用于计量和限速,其结构示意图如下图所示。Meter表项可以针对流制定对应的限速等规则,从而实现丰富的QoS功能。Meter表和端口队列不同,Meter表项是面向流的,而不是面向端口的,所以更细致、更灵活。

OpenFlow通道
OpenFlow通道是控制器和交换机通信的通道,通道中转发的数据为OpenFlow消息/报文。OpenFlow的报文分为Controller-to-Switch、Asynchronous和Symmetric三大类。
Controller-to-Switch类型的报文主要由控制器初始化并发送给交换机,Asynchronous类型的报文是交换机异步上报给控制器的报文,而Symmetric类报文则是无须等待对方请求、双方都可以任意发送的报文。
Controller-to-Switch报文
Controller-to-Switch是由控制器初始化并下发给交换机的报文类型,其可能会要求交换机回复对应的报文,此类型报文包含的主要报文类型介绍如下。
-
Features:Features类型的报文分为Request和Reply两种,其中控制器可以主动初始化并发送Feature_Request报文,请求交换机回复其特性信息,其报文只有数据报头,没有消息体(Body)。交换机在收到Features_Request报文之后,将通过Features_Reply报文回复交换机的特性和交换机端口的特性信息。通常,控制器会在交换机的OpenFlow连接建立完成之后马上发送一个请求报文来获取交换机的特征信息。
-
Contfiguration:其包含请求、回复和设置三种报文。控制器可以设置和请求交换机的配置信息,交换机则需执行配置和回复配置报文。
-
Modify-State:修改状态型报文由控制器下发,用于修改交换机的流表、组表、Meter表及端口状态。
-
Read-State:读取状态信息由控制器发出,用于获取交换机的状态信息,包括流表、组表、MeterTable及端口的统计信息。
-
Packet-out:Packet-out类型报文由控制器发出,用于将数据包发送到交换机的指定端口。Packet-out报文一般用于响应Packet-in报文的处理,经常跟随在Flow-mod报文之后,用于指挥交换机将缓存数据发送或直接发送数据.Packet-out必须携带一个Buffer id来定位缓存在交换机上的数据,当Buffer id为-1时,表明该数据包没有被交换机缓存。此外,Packet-out还需要携带指导数据处理的动作集,如果动作集为空则交换机会将数据包丢弃。
-
Barrier:BarriersRequesyReply用于确保操作顺序执行。控制器可以向交换机发送Request报文。交换机接收到Request报文之后,将Request报文之前所有的报文处理完成之后,处理BarrierRequest请求:回复控制器一个BarrierReply报文,其报文ID和请求报文一致,告知控制器在BarrierRequest报文之前到来的报文已经处理完成。Barrier类型的报文类似于设置一个障碍或者触发器,用来告知控制Barrier之前的动作均已执行,其通常用来确保动作执行顺序,保持策略一致性。
-
Role-Request:此类型报文用于控制器请求其自身在交换机端的角色,也可以用于设置控制器的角色。一般用于交换机与多控制器有连接的场景。
-
Asynchronous-Configuration:异步配置报文可以用来设置异步报文的过渡器,从而使得在多控制器场景下,控制器可以选择性过滤异步报文,只接收感兴趣的报文。一般在OpenFlow连接建立完成之后进行设置。
Asynchronous报文
Asynchronous报文是由交换机异步发送给控制器的报文,无须等待控制器请求。交换机通过异步报文告知控制器新数据包的到达和交换机状态的改变。主要的异步报文类型描述如下。
-
Packet-in:将数据包发送给控制器。在支持单流表的OpenFlow协议版本中,触发Packet-in的原因可能是流表项的动作指导,也可能是因为匹配不到流表项。但在高版本的多级流表设计下,将默认下发一条Table-Miss流表项,其匹配域均为空,任何报文都能匹配成功。Table-Miss的作用是将匹配其他流表失败的数据发送给控制器。若交换机配置信息中指示将数据包缓存在交换机中,则Packet-in报文还将携带着指定长度的数据包数据及其在交换机上缓存的Bufferid,携带的数据包默认长度是128字节。若交换机不缓存数据包,则由Packet-in报文携带全部数据并发送给控制器。Packet-in报文通常会触发Packet-out报文或者Flow-mod报文。
-
Flow-Removed:当OFPFFSEND_FLOW_REM标志位被置位时,交换机将会在流表项失效时通知控制器流表项被移除的消息。触发流表项失效的原因可以是控制器主动删除或者流表项超时。
-
Port-status:当端口配置或者状态发生变化时,用于告知控制器端口状态发生改变。
-
Role-status:当控制器的角色发生变化时,交换机告知控制器其角色变化。
-
Controller-Status:当OpenFlow连接发生变化时,告知控制器这个变化。
-
Flow-monitor:告知控制器流表的改变。控制器可以设置一系列监视器来追踪
流表的变化。
Symmetric报文
Symmetric可以由控制器和交换机双方任意一方发送,无须得到对方的许可或者邀请。主要类型的介绍如下。
-
Hello:Hello报文用于交换机和控制器之间的OpenFlow通道建立初期,用于协商版本等内容。
-
Echo:EchoRequestyReply可以由交换机和控制器任意一方发出。每个Request报文都需要一个Reply报文回复。其主要用于保持连接的活性,但同时也支持携带消息内容,可用于时延或带宽测试。
-
Error:错误报文用于交换机或控制器,告知对方错误。一般而言,多被用于交换机告知控制器请求发生的错误。
-
Experimenter:实验报文是提供OpenFlow报文功能范围之外功能的标准方式,可以用于实验场景。
OpenFlow通信流程
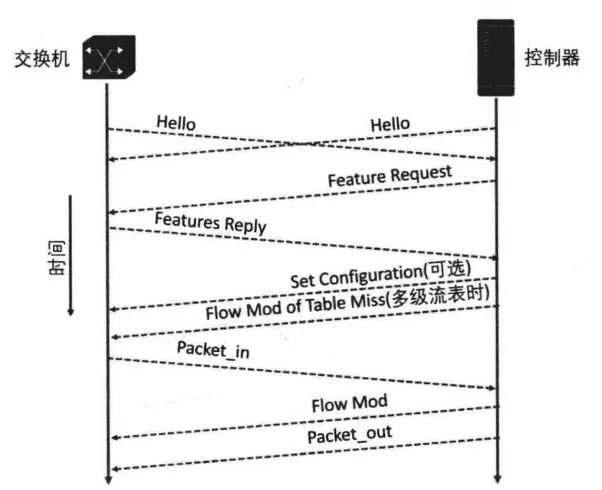
当交换机和控制器建立完Socket通信之后,会相互发送Hello报文,用于协商协议版本。完成协议版本协商之后,控制器会向交换机下发Features Request报文,交换机则需回复Feature Reply报文。控制器根据交换机支持的特性,可以完成交换机的相关配置。配置完成之后,进入正常通信状态。如果OpenFlow版本支持多级流表,控制器还需要下发Table-Miss流表项到交换机。
当数据包匹配流表失败或者匹配到Table-Miss时,交换机将其Packet-in到控制器,控制器根据控制逻辑可选择回复Packet-out或者下发Flow-mod指导交换机处理数据流。如果配置了Flow-Removed标志位,则当流表项过期时,交换机将向控制器回复Flow-Removed报文。
其他异步报文的发生则可以发生在任意时刻。为保持OpenFlow连接的活性,控制器应周期性地向交换机发送Echo报文。
广义SDN南向协议
OF-Config
在OpenFlow协议的规范中,控制器需要和配置完成的交换机进行通信。而交换机在正常工作之前,需要对其功能、特性及资源进行配置才能正常工作。而这些配置超出了OpenFlow协议规范的范围,理应由其他的配置协议来完成。OF-Config(OpenFlow Management and Configuration Protocol)协议就是一种OpenFlow交换机配置协议。
OF-Config协议与OpenFlow及OpenFlowSwitch之间的关系如下图所示。
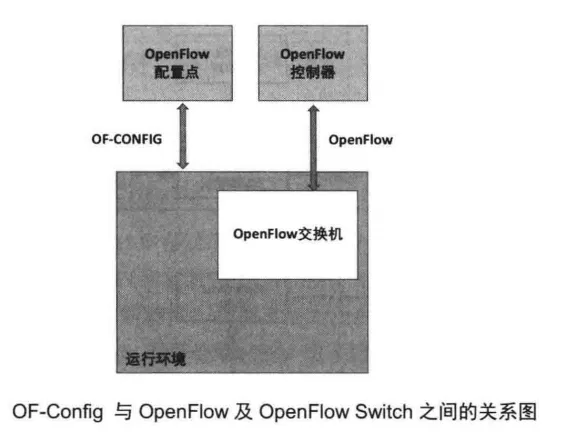
OF-Contig协议主要分为Server和Client两部分,其中Server运行在OpenFlow交换机端,而Client运行在OpenFlow配置点上。本质上,OpenFlow配置点就是一个普通的通信节点,其可以是独立的服务器,也可以是部署了控制器的服务器。通过OpenFlow配置点上的客户端程序可以实现远程配置交换机的相关特性,比如连接的控制器信息及端口和队列等相关配置。最新的1.2版本的OF-Contfig协议支持OpenFlow1.3版本的交换机配置,其支持的配置内容如下:
-
配置datapath(在OF-Contfig协议中称为OpenFlow逻辑交换机)连接的控制器信息,支持配置多个控制器信息,实现容灾备份。
-
配置交换机的端口和队列,完成资源的分配。
-
远程改变端口的状态及特性。
-
完成OpenFlow交换机与OpenFlow控制器之间安全链接的证书配置。
-
发现OpenFlow逻辑交换机的能力。
-
配置VXLAN、NV-GRE等隧道协议。
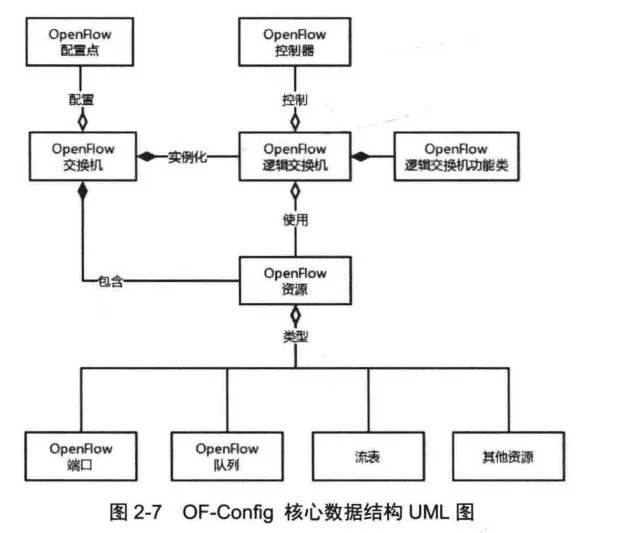
OF-Contfig采用XML来描述其数据结构,其核心数据结构的UML图如图2-7所示。其中,OpenFlow交换机是由OpenFlow逻辑交换机类实例化出来的一个实体,用于与OpenFlow配置节点通信,并由配置节点对其属性进行配置。OpenFlow逻辑交换机是指对OpenFlow交换机实体的逻辑描述,用于指导物理交换机进行相关动作,也是与OpenFlow控制器通信的实体。OpenFlow逻辑交换机拥有包括端口、队列、流表等资源。
作为OpenFlow的伴侣协议,OF-Contfig很好地填补了OpenFlow协议规范之外的内容。在OpenFlow协议的SDN框架中,需要如OF-Contfig这样的配置协议来完成交换机的配置工作,包括配置控制器信息等内容。当交换机和控制器建立连接之后,将通过OpenFlow协议来传递信息。从面向对象的角度考虑,OpenFlow协议是控制器指导交换机进行数据转发的协议,其规范的范围理应仅包括指导交换机对数据流进行操作,而不包括对交换机的资源进行配置。所以交换机配置部分的工作应该由OF-Contfig等配置协议来完成。
感觉类似于DHCP。。。
| - | OpenFlow | OF-Config |
|---|---|---|
| 设计动机 | 通过修改流表项等规则来指导OpenFlow交换机对网络数据包进行修改和转发等动作 | 通过远端的配置点来对多个OpenFlow交换机进行配置,简化网络运维工作 |
| 传输 | 通过TCP、TSL或者SSL来传输OpenFlow报文 | 通过XML来描述网络配置数据,并通过NETCONF来传输 |
| 协议终结点 | OpenFlow控制器(代理或者中间层在交换机看来就是控制器);OpenFlow交换机/datapath | OF-Config配置点;支持OpenFlow的交换机 |
OVSDB
OVSDB(The Open vSwitch Database Management Protocol,OVS的数据库管理协议)是由SDN初创公司Nicira开发的专门用于Open vSwitch(以下简称OVS)的管理和配置的协议。OVSDB与OF-Contfig类似,都是OpenFlow交换机配置协议,但两者的区别在于:
OVSDB仅用于OVS的配置和管理,而OF-Contig可以用于所有支持OpenFlow的软件或者硬件的交换机。
OVSDB协议的架构也和OF-Contfig类似,同样分为Server端和Client端,具体如图2-8所示。Server端对应的是ovsdb-server进程,而Client则运行在远端的配置节点上。配置节点可以是部署控制器的服务器,也可以是其他的任意终端。从图2-8中可知,OVS可以由ovsdb-servers、ovs-vswitchd和Forwarding-Path三个主要模块组成。
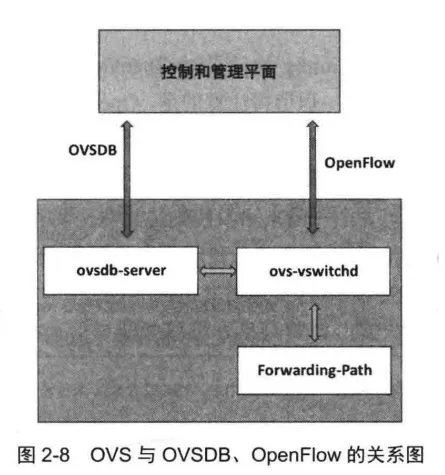
其中,ovsdb-server进程负责存储OVS相关数据并对接OVSDB接口;ovs-vswitchd进程提供OpenFlow接口,用于和控制器相连;ForwardingPath模块则负责数据转发相关行为。通过OVSDB协议可以完成OVS实例的配置和管理,其主要支持的动作如下:
-
创建、修改和删除datapath,也即网桥。
-
配置datapath需要连接的控制器信息,包括主控制器和备份控制器。
-
配置OVSDB服务器需要连接的管理端。
-
创建、修改和删除datapath上的端口。
-
创建、修改和删除datapath上的隧道接口。
-
创建、修改和删除队列。
-
配置QoS策略。
-
收集统计信息。
OVSDB协议采用JSON进行数据编码,并通过RPC来实现数据库的各种操作。其支持的RPC方法及其介绍如下:
-
ListDatabases:获取OVSDB能访问的所有数据库。
-
GetSchema:获取某个数据库的描述信息。
-
Transact:按照顺序执行动作集。
-
Cancel:取消指定ID的动作,属于JSON-RPC消息,无回复报文。
-
Monitor:监视指定数据库的动态。
-
UpdateNotification:由服务器发出的更新通知。
-
MonitorCancellation:取消监视。
-
LockOperations:获取某数据库的锁操作。
-
LockedNotification:获得锁的通知。
-
StolenNotification:请求从其他锁拥有者处获取数据锁。
-
Echo:用于保持通信活性。
通过以上的RPC方法就可以实现对OVS的配置.为了满足多配置节点协作的要求,OVSDB设计了LOCK等操作,从而保证数据读写的顺序,保证数据一致性。以上的RPC方法中最重要的一个动作是Transact。一般的,Transact动作会携带一系列的数据库操作指令,从而对数据库的具体数据项进行操作,具体的操作包含如下动作:
-
Insert:往表中插入数据。
-
Select:从表中筛选数据项。
-
Update:更新表项。
-
Mutate:对数据库中的数据进行运算。
-
Delete:删除数据库内容。
-
Wait:等待条件成立执行动作。
-
Commit:提交数据持久化请求。
-
Abort:取消桃操作。
-
Comment:评价,为操作添加必要说明。
-
Assert:断言操作,如管理端不拥有数据修改锁则取消操作。
NETCONF
NETCONF是由IETF(InternetEngineeringTaskForce)的NETCONF小组于2006年12月提出的基于XML的网络配置和管理协议。在NETCONF之前提出的SNMP的设计目的是实现网络设备的配置,但是由于SNMP在网络配置方面能力较差,所以在实际应用中常被用于网络监控而非网络配置。为了弥补SNMP的不足,IETF提出了基于XML的NETCONF协议,其具有很强的数据描述能力和良好的可拓展性。由于NETCONF在网络配置方面的高效,NETCONF成为了许多网络设备的配置协议,促进了网络设备自动化配置的发展。也正因为它高效的优点,NETCONF也被OpenDaylight等多种SDN控制器支持。
NETCONF支持对网络设备配置信息的写入、修改和删除等操作,其数据采用XML格式描述,其操作是通过RPC(Remote Procedure Call)来实现的,整体报文通过传输层协议进行传输。NETCONF协议层次图如图2-9所示,其中包括如下四个子层。
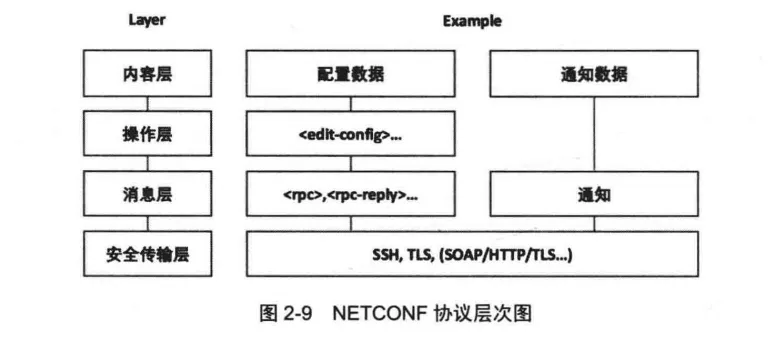
-
内容层:包含配置数据和通知数据等具体的数据内容。
-
操作层:定义了edit-config、get-config、delete-contfig和copy-config等操作,实现数据库操作。
-
消息层:提供RPC接口,用于实现远程调用和通知。
-
安全传输层:提供安全、可靠传输的安全传输层。在NETCONF标准中并没有规定采用什么样的传输协议,所以可以采用SSH、TLS或SOAP等其他协议作为传输协议。
作为一个网络配置协议,NETCONF协议最突出的优点是定义了一系列完整的操作动作。这些动作都可以通过RPC来执行,从而完成网络设备配置。除了这些基本的操作以外,还可以通过NETCONF的Capabilities来拓展新的内容,所以NETCONF具有很好的可拓展性,可以满足多种具体需求。
NETCONF虽然是多个SDN控制器支持的南向协议之一,但它无法指导交换机进行数据转发处理,它的定位依然还是网络设备配置协议,与OF-Contfig和OVSDB类似。对于传统设备而言,使用NETCONF等协议进行配置之后即可开始工作,无须OpenFlow等其他协议来控制数据转发逻辑。而对于SDN设备,不仅需要NETCONF这类配置协议来配置,还需要OpenFlow等协议来指导交换机的数据交换等功能。
OpenFlex
OpFlex口是思科提出的一个可拓展SDN南向协议,用于控制器和数据平面设备之间交换网络策略。自SDN出现之后,其数控分离的设计使得交换机趋向于白盒(White Box)化,严重冲击了传统设备厂商的市场地位。为了应对这一趋势,网络设备厂商领域的领头羊思科推出了ACI(Application Centric Infrastructure),即以应用为中心的基础设施。ACI的技术重点在底层的硬件设施,而不在控制平面,但ACI支持软件定义数据平面的策略,所以ACI也是一种广义的SDN实现方式。在ACI架构中可以通过集中式的APIC(Application Policy Infrastructure Controller)来给数据平面设备下发策略,实现面向应用的策略控制。APIC和数据平面设备之间的南向协议就是采用了OpFlex。
OpFlex可以基于XML或者Json来实现,并通过RPC来实现协议操作。OpFlex的架构如图2-10所示。目前OpenDaylight(ODL)已经支持OpFlex协议,数据平面的交换设备如OVS在部署OpFlex代理之后也可以支持OpFlex。
在OpFlex协议中,协议的服务端是逻辑集中式的PR(Policy Repository),客户端为分布式的交换设备或四到七层的网络设备,称为PE(Policy Element)。在ACI中,PR可以部署在APIC上,也可以部署在其他网络设备上。PR用于解析PE的策略请求及给PE下发策略信息,而PE是执行策略的实体,其是软件交换机或者支持OpFlex的硬件交换机。
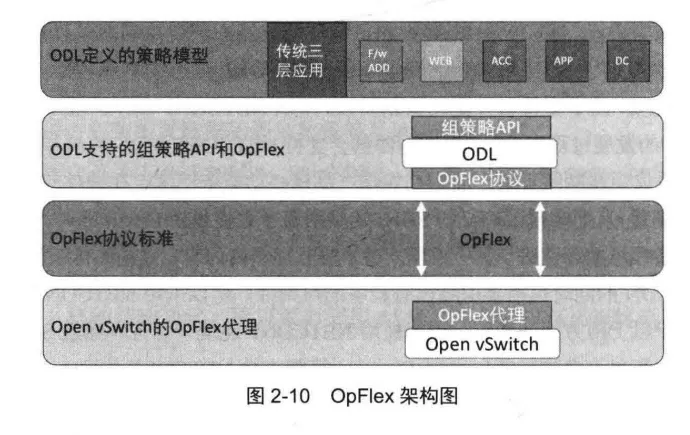
思科的官方文件中描述到OpFlex协议是一种声明式控制(Declarative Control)协议,而OpenFlow则是一种命令式的控制(Imperative Control)协议。声明式控制只通知对象要达到一种要求的状态,但是并没有规定其通过指定的方式去达到这个状态。
在ACI中,APIC只下发相应的网络策略,而如何实现这一策略,还需要智能的网络设备来具体实现。
然而对于OpenFlow而言,需要精确地告知交换机具体的动作,才能完成数据的处理。
ACI的这种设计不仅使得ACI实现了软件定义的网络框架,也保障了ACI依然以底层智能设备为中心,从而既迎合了SDN的发展趋势又巧妙地保留了技术壁垒,进而使得思科依然可以在其领先领域来面对SDN的冲击。
XMPP
XMPP(Extensible Messagingand Presence Protocol)是一种以XML为基础的开放式即时通讯协议,其因为被GoogleTalk使用而被大众所接触。
XMPP由于其自身具有良好的可拓展性,从而可以被灵活应用到即时通讯、网络设备管理等多种场合。XMPP也被开源控制器OpenContrail采用作为南向协议,从而逐渐被应用到SDN领域。
采用XMPP的优点在于可以统一管理传统设备和SDN设备。用户的网络中可能存在大量的传统设备,采用兼容性和拓展性更好的XMPP可以统一管理SDN网络和现有的网络,从而保护用户的已有资产,这是采用XMPP作为南向协议的最大优势之一。
不过作为一个南向协议,XMPP的功能粒度还很粗,没有达到OpenFlow的细粒度。
PCEP
PCEP(Path Computation Element Communication Protocol)是由IETF提出的路径计算单元通信协议,常为流量工程(Traffic Engineering)提供路径计算服务。PCEP的
设计其有很好的弹性和可拓展性,易于拓展,因此适用于多种网络场景。
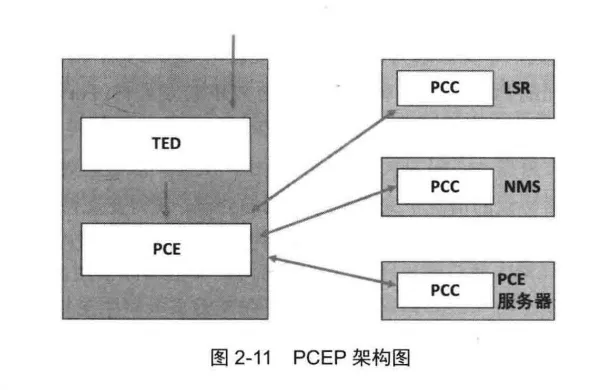
在PCEP协议架构中,定义了PCC(Path Computation Client)和PCE(Path Computation Element),其框架如图2-11所示。
PCC和PCE的部署位置都很灵活。PCC可以是一台交换路由设备,也可以和NMS(NetworkManagerSystem)部署在同一台服务器中。同样地,PCE可部署于专门的服务器中,也可以和NMS部署在一台服务器中。
PCC节点用于发起路径计算的请求,以及执行路径计算的结果。PCE是远端的PCEP服务端,用于接收PCC的路径请求,然后将计算结果回复给PCC,从而指导路由器等转发设备进行数据转发行为。在PCEP架构中,PCE和PCE也可以相互通信,从而实现水平架构或者层级式多PCE系统,提升系统的可用性。虽然PCEP没有使得数据平面和控制平面完全分离,但是PCEP把路径计算的控制逻辑从转发设备中抽离到远端,实现了部分数据平面和控制平面的分离。通过远端服务器的软件编程,可以指导底层路由或转发设备实现数据的转发和路由。
PCEP仅定义了PCC和PCE的通信标准,如建立连接、发起路径计算请求和回复路径结果等内容。计算路径所需的网络信息的收集需要通过其他的渠道获取。所以IETF的PCEP工作组又把OSPF、IS-IS等标准拓展了一道,添加了OSPF的PCEP拓展和IS-IS的PCEP拓展等多个标准,使得目前的路由协议可以支持收集网络信息,并将信息写入到TED(Traffic Engineering Database)中。当PCE计算路径时,可通过读取TED中的网络信息去计算符合要求的最优路径。
PCEP支持多种设备,也被多种路由协议支持,因此PCEP在TE领域得到了广泛的应用。PCEP协议实现的架构也是一种SDN,将OpenFlow和PCEP协议结合使用可以实现OpenFlow网络和传统网络的统一管理和调度。但本质上,PCEP只能用于TE场景,其可编程能力还不完善,也并非专门为SDN设计的。
完全可编程南向协议
POF
POF(Protocol Oblivious Forwarding)是由华为宋浩宇等人提出的SDN南向协议,是一种SDN实现方式,中文意思为协议无关转发。
与OpenFlow相似,在POF定义的架构中分为控制平面的POF控制器和数据平面的POF转发元件(Forwarding Element)。
在POF架构中,POF交换机并没有协议的概念,它仅在POF控制器的指导下通过{offset,length}来定位数据、匹配并执行对应的操作,从而完成数据处理。
此举使得交换机可以在不关心网络协议的情况下完成网络数据的处理,使得在支持新协议时无须对交换机进行升级,仅需升级控制平面即可,大大加快了网络创新的进程。
POF的设计思想与PC(PersonalComputer,个人电脑)的设计思想类似,所以其架构和PC的架构也类似,两者的对比如图2-12所示。POF转发设备无须关心具体的协议语义,只需关心底层的数据操作即可。
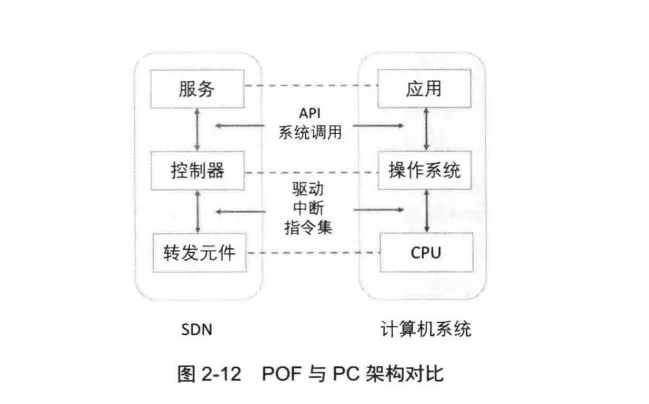
针对OpenFlow无状态的缺陷,POF设计了相关指令使得POF交换机可以维护简单的状态机。在条件满足时,POF交换机可以主动地创建、修改和删除流表等操作。
在主动执行指令之后,交换机需要异步通知控制器发生的改变,从而实现数据的同步。
P4
面对OpenFlow存在的可编程能力不足的问题,除了华为公司提出的POF以外,学术界也提出了颠覆性的P4。
简介
P4是由Pat Bosshart等人提出来的“协议无关数据包处理编程语言”。P4语言定义了一系列的语法,也开发出了P4的编译器,支持对P4转发模型的协议解析过程和转发过程进行编程定义,实现了真正意义上的协议无关可编程网络数据平面。
本质上,P4不是OpenFlow2.0,虽然P4和OpenFlow都关注开放网络,但是P4所关注的是另外一种网络需求:数据平面的可编程。
与POF提出的目的类似,P4提出的目的也是为了解决OpenFlow编程能力不足及其设计本身所存在的可拓展性差的难题。
OpenFlow只能在已经固化的交换机数据处理逻辑之上,通过流表项指导数据流处理,而无法重新定义交换机处理数据的逻辑,从而灵活支持新协议,这是OpenFlow所欠缺的编程能力。
P4的优点:
-
可灵活定义转发设备数据处理流程,且可以做到转发无中断的重配置。OpenFlow所拥有的能力仅是在已经固化的交换机数据处理逻辑之上,通过流表项指导数据流处理,而无法重新定义交换机协议解析和数据处理等逻辑,但P4编程语言具有对交换机的协议解析流程和数据处理流程进行编程的能力。
-
转发设备协议无关转发。交换设备无须关注协议语法语义等内容,就可以完成数据处理。由于P4可以自定义数据处理逻辑,所以可以通过控制器对转发设备编程实现协议处理逻辑。即可以通过软件来定义交换机支持的协议功能,包括数据包的解析流程、匹配所需的表、需要执行的动作列表等内容。在完成协议处理逻辑定义后,P4支持下发对应的匹配和动作表项去指导交换机进行数据的处理和转发。
-
设备无关性。正如采用C语言或者Python语言写上层应用代码时并不需要关心CPU的相关信息一样,使用P4语言进行网络编程同样无须关心底层设备的具体信息。P4的编译器会将通用的P4语言处理逻辑编译成设备相关的指令并写入转发设备,从而完成转发设备的配置和编程。
原理
P4的抽象转发模型如图2-15所示,其中的解析器是可编程协议解析器,可实现自定义的数据解析流程。
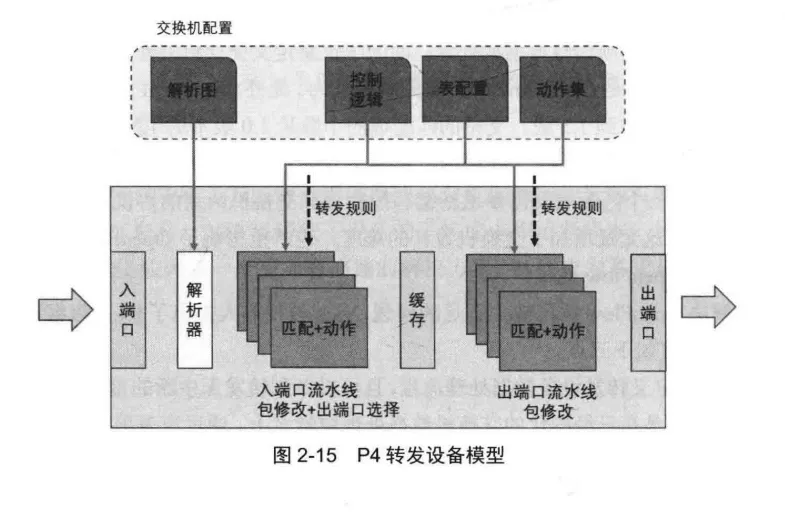
数据包在完成解析之后需要经过和OpenFlow流水线类似的Match-Action(匹配-动作)流水线,其流水线支持串行和并行两种操作。
P4设计的匹配过程分为入端口流水线和出端口流水线两个分离的数据处理流水线。
与OpenFlow相比,P4的设计有如下三个优点:
-
可编程的协议解析模块,而不像OpenFlow交换机的固定解析逻辑;
-
支持并行和串行执行Match-Action操作,而OpenFlow仅支持串行操作;
-
支持协议无关的转发。
从P4抽象转发模型中可以了解到交换机的工作流程,可以分为数据包解析和数据包转发操作两个子流程。
P4支持定义数据包解析过程和数据转发过程。
在定义交换机处理逻辑时,首先需要定义数据包解析器的工作流程,然后再定义数据包转发的控制逻辑。
定义解析器时需要定义数据报文格式,以及不同协议之间的跳转关系,从而定义完整的数据包解析流程。
完成解析器定义之后,需要定义转发控制逻辑,内容包括用于存储转发规则的匹配表的定义及转发表之间的依赖关系的定义。
这些控制逻辑代码通过P4的编译器编译成TDG(Table Dependency Graph),然后写入到交换机中。TDG用于描述匹配表之间的依赖关系,定义了交换机处理数据的流水线。
图2-16就是一个L2/L3交换机TDG的例子。
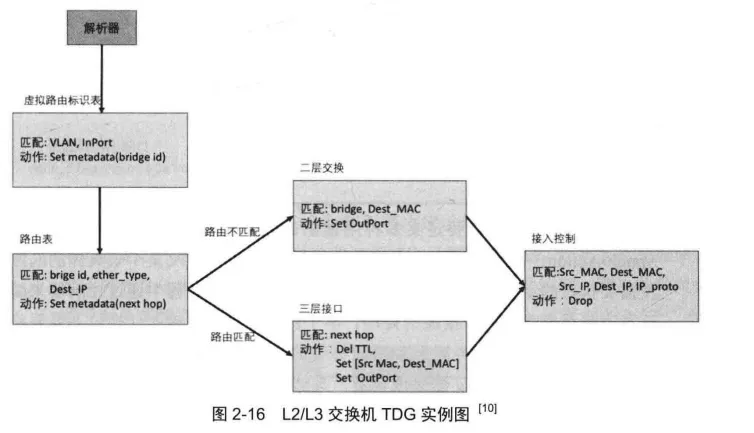
从图中可以看出,从解析器模块解析出来的数据先经过了虚拟路由标识(Virtual Routing Identification)表,再经过路由表,基于匹配的结果,将数据包跳转到二层交换表或者三层接口表进行处理,最后还要经过接入控制表的处理,从而完成数据包的处理。
每一个P4程序包含如下5个关键组件:Header、Parser、Table、Action和Control Programs,其具体介绍如下。
-
Header(报头):数据包的处理都需要根据报头的字段内容来决定其操作。所以,P4中也需要定义对应的报头,报头本质上就是有序排列的协议字段序列。报头的描述由有序的字段名称和对应的字段长度组成。
-
Parser(解析器):在定义了报头之后,还需要定义报头协议字段之间的关系,以及数据包解析流程。比如ethernet的ethertype=0x0800时应该跳转到IPv4的Header进行后续解析。所有的解析均从start状态开始,并在stop状态或者错误之后结束。解析器将字节流的信息解析为对应的网络协议字段,用于后续的流表项匹配和动作执行。
-
Table(表):,P4中需要定义多种用途的表来存储匹配表项。其表的格式为Match-Action,即匹配域和对应的执行动作。P4语言定义某个表具体的匹配域及需要执行的动作。而具体的流表项需要在网络运行过程中通过控制器来编程下发,从而完成对应数据流的处理。
-
Action(动作):与OpenFlow的动作类似,不过P4的动作是抽象程度更高的协议无关动作。P4定义了一套协议无关的原始指令集,基于这个指令集可以实现复杂的协议操作。P4支持的原始指令集包括set_fieldt、add_header和checksum等为数不多的指令。复杂的动作将通过这些原始指令集组合去实现,调用这些指令时所需的参数可以是数据包匹配过程中产生的metadata。
-
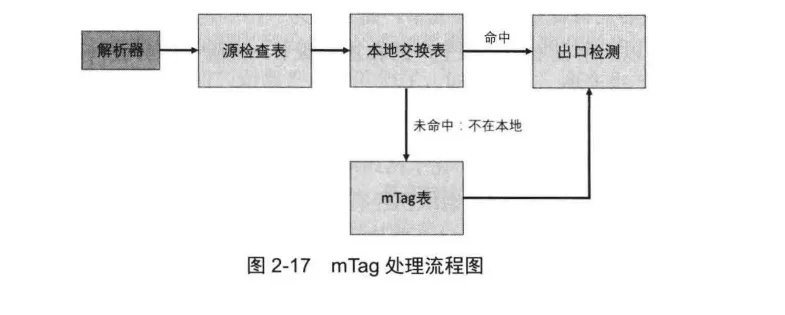
Control Program〔(控制程序),控制程序决定了数据包处理的流程,即数据包在不同匹配表中的跳转关系。当表和动作被定义和实现之后,还需要控制程序来确定不同表之间的控制流。P4的控制流包括用于数据处理的表,判决条件及条件成立时所需采取的操作等组件。以mTag的处理为例,其过程如图2-17所示。
完成一个P4语言程序之后,需要通过P4的编译器将程序编译并写入到交换机中,其主要分为数据解析逻辑的编译写入和控制流程的编译写入。
数据解析部分用于将网络字节流解析为对应的协议报文,并将报文送到接下来的控制流程中进行匹配和处理。控制流程的编译和写入主要分为两步:
第一步需要将P4的程序编译,然后生成设备无关的TDG(Table Dependency Graph);
第二步根据特定的底层转发设备的资源和能力,将TDG映射到转发设备的资源上。
目前,P4支持在多种转发设备上使用,包括软件交换机、拥有RAM和TCAM存储设备的硬件交换机、支持并行表的交换机,也支持在流水线最后才执行动作的交换机及拥有少量表资源的交换机。
SDN控制平面
SDN控制平面简介
SDN是一种控制平面与数据平面分离的集中式控制网络架构",其网络架构1.1版本如图3-1所示。SDN 的控制平面是SDN的大脑,指挥数据平面的转发等网络行为。控制平面提供了网络可编程能力,使得开发者可以在控制平面上开发网络应用,并直接部署到数据平面,指导数据平面的数据交换等业务。
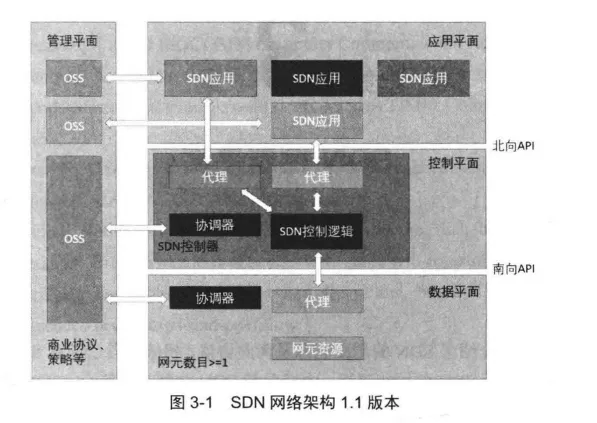
控制平面可根据功能逻辑划分为南向接口层、控制核心层、北向接口层和应用层。
其中南向接口层是关于南向协议的相关实现;
控制核心层是控制器的核心,主要提供网络资源的管理、事件系统等服务;
北向接口层包含了面向应用的编程接口,主要为上层应用提供SDN编程接口服务;
而应用层是网络应用服务的相关实现。
一些典型的控制器,比如SDN发展初期时出现的NOX和POX,
性能更好、体验更好的OpenFlow控制器Ryu3和Floodlight,以及现在正流行的网络操作系统级别的控制平台OpenDaylight和ONOS。
SDN开源控制器
适合科研应用的POX/NOX、RYU和Floodlight
适合工程实践使用的OpenDaylight和ONOS。
科研工作者建议使用Ryu、Floodlight 等控制器,而较大型的OpenDaylight和ONOS则更适合工程部署。
NOX/POX
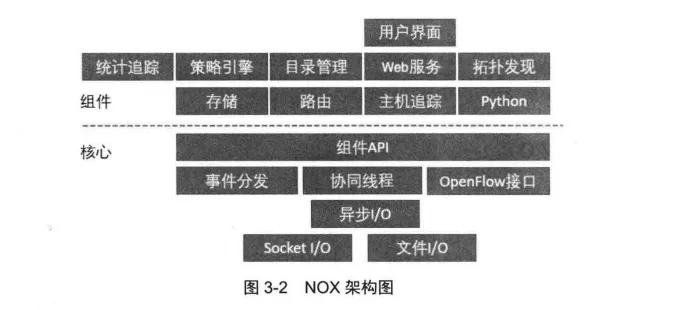
NOX的底层使用C++编写,支持OpenFlow1.0协议,提供C++版本的OpenFlow1.0的API,具有高性能的异步网络I/O。NOX架构图如图3-2 所示,其架构可大致分为核心层和外围组件两部分,其中核心层包括事件分发、异步I/O、文件I/O和OpenFlow接口等模块。OpenFlow 接口模块向上层提供了支持OpenFlow的接口,以便开发者使用。
由于采用C++开发难度太高,会影响了网络业务开发的效率,所以Nicira公司于2011年推出了NOX的增强版POX。
POX使用Python语言编写。由于Python语言支持多平台,所以POX支持在Linux、MacOS和Windows等系统使用。
在功能方面,POX的核心部分和NOX的核心部分一致。此外,POX还提供了基于Python语言的OpenFlow API及如Topology Discovery等可复用的基础模块。
POX也可以使用NOX的GUI和虚拟化工具。性能方面,POX要优于NOX,尤其是在使用PyPy运行的情况下。
由于Python语言简单高效,所以POX应用的开发效率很高,适合用于快速开发和功能验证的科研场景。当然,POX也有缺点。
POX代码简单,所以缺少的模块也比较多,功能不够全面。另一方面,相比Ryu的封装性,POX代码稍显凌乱,代码结构不够优秀,可拓展性不足。
Ryu
Ryu代码模块化风格明显,其整体架构与其他SDN控制器类似,大致可以分为控制层和应用层,其架构如图3-4所示。控制层主要包含协议解析、事件系统、基本的网络报文库类和内建应用等模块,而应用层则是基于控制层提供的API编写的网络应用,以及支持Ryu和其他系统协同工作的组件和模块。Ryu通过南向接口与数据平面的设备进行通信,通过北向接口完成应用层和控制层的通信。面向北向,Ryu 提供了REST API和RPC等接口,允许外界的进程与Ryu进行通信。因此实验人员可以在OpenStack或者其他程序上与Ryu通信,进而控制SDN网络。
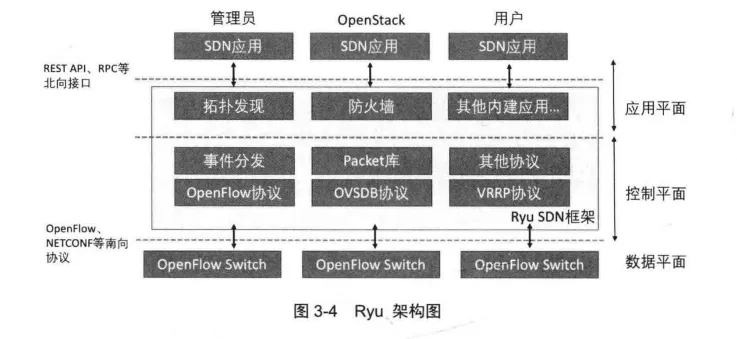
Ryu是一个特性丰富的SDN控制器。南向协议方面,不仅支持从1.0 到1.5版本OpenFlow协议的特性及Nicira 公司的拓展,还支持如OF-Config、OVSDB、VRRP和NET-CONF等其他南向协议。
北向方面,Ryu 可以作为OpenStack的插件,也支持和开源入侵检测系统Snort协同合作。 此外,Ryu 也支持使用Zookeeper来实现高可用性(High Availability)的目标。
在内建应用方面,Ryu 源码中已经包含了许多基础的应用,比如简单的二层交换、路由、最短路径和简单的防火墙。
Ryu代码风格优美,模块之间逻辑清晰,是初学者的最佳选择。
Floodlight
Floodlight和其他控制器架构类似,它的架构可以分为控制层和应用层两个主要部分,其架构如图3-5 所示。
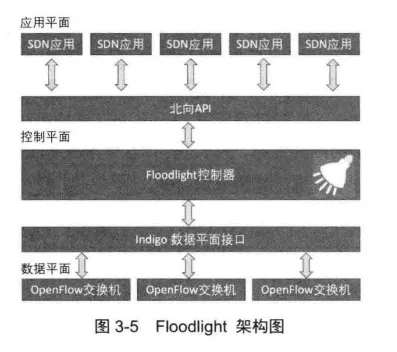
应用层通过北向API来与控制层实现信息的交互;控制层通过南向接口和数据平面通信,实现对数据平面的控制。
Floodlight 的架构清晰,模块之间低耦合,基础模块代码非常优秀。所以,Big Switch等公司选择在Floodlight开源版本上二次开发出商业版本。
此外,ON.LAB最新推出的ONOS( Open Network Operating System)控制器核心模块也采用了Floodlight的核心模块作为其底层的解析模块。
Floodlight项目由控制器和基于控制器开发的应用组成。Floodlight支持丰富的特性,每个特性由模块化的若干个组件模块组成。Floodlight 的模块可以分为如图3-6 所示的Floodlight控制器、模块应用、REST API、REST应用和Java API等部分。
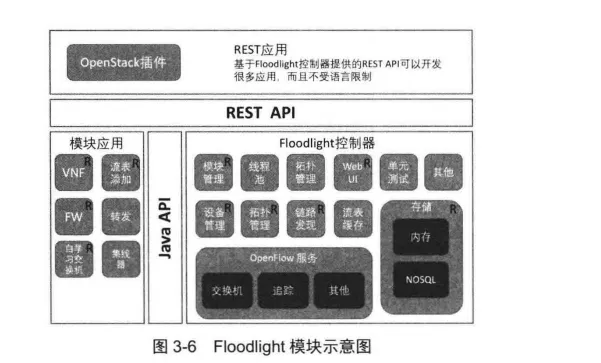
Floodlight控制器是Floodlight的核心模块部分,包括模块管理、线程池、Web UI、设备管理及OpenFlow相关服务。核心部分完成了SDN控制器的基础功能,并向应用层提供API,使得开发者可以在此基础之上开发SDN应用。模块应用部分包含了如集线器、自学习交换机等模块化的基础网络应用。
Floodlight支持的南向协议目前只有OpenFlow,且对于OpenFlow版本支持得比较少,这是Floodlight 特性上的劣势。
优势方面,Floodlight 开放的模块化架构,使得Floodlight易于拓展和提升; Floodlight 依赖少,易于安装; Floodlight 支持混合组网,即支持OpenFlow和非OpenFlow交换机的混合网络。
此外,Floodlight 也实现了OpenStack的插件,可与OpenStack 集成协同工作。
最后,性能方面的优势是Floodlight 最大的优势。Floodlight的稳定和高效掩盖了其开源社区活跃度不够高、版本演进过慢的缺点。
老套路了,除了稳定和性能我实在是想不出还有什么理由能够掩盖这些缺点了……
OpenDaylight
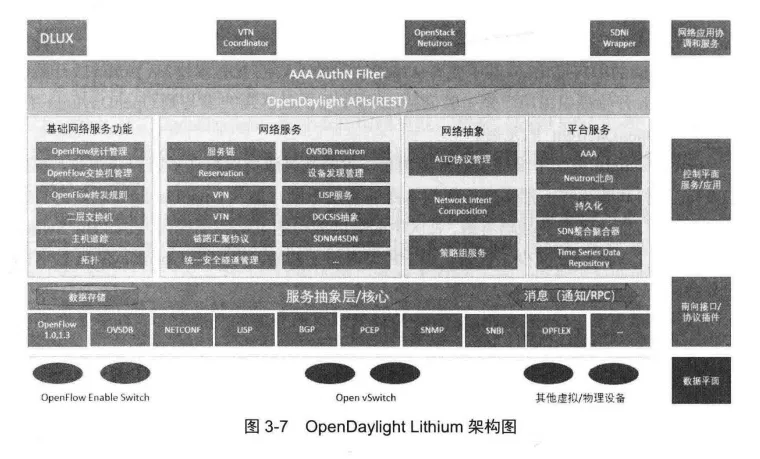
OpenDaylight是一个高度可用、模块化、可扩展、支持多协议的控制器平台,可以作为SDN管理平面管理多厂商异构的SDN网络。它提供了一个模型驱动服务抽象层(MD-SAL),允许用户采用不同的南向协议在不同厂商的底层转发设备上部署网络应用程序。
OpenDaylight的架构如图3-7所示,可分为南向接口层、控制平面层、北向接口层和网络应用层。南向接口层中包含了如OpenFlow、NET-CONF 和SNMP等多种南向协议的实现。
控制平面层是OpenDaylight的核心,包括MD-SALI4、基础的网络功能模块、网络服务和网络抽象等模块,其中MD-SAL是OpenDaylight最具特色的设计,也是OpenDaylight架构中最重要的核心模块。无论是南向模块还是北向模块,或者其他模块,都需要在MD-SAL中注册才能正常工作。
MD-SAL也是逻辑上的信息容器,是OpenDaylight控制器的管理中心,负责数据存储、请求路由、消息的订阅和发布等内容。
北向接口层包含了开放的REST API接口及AAA认证部分。应用层是基于OpenDaylight北向接口层的接口所开发出的应用集合。
OpenDaylight基于Java语言编写,采用Maven来构建模块项目代码。
为了实现OpenDaylight 良好的拓展性,OpenDaylight 基于OSGi (Open ServiceGateway Initiative)框架运行,所有的模块均作为OSGi框架的bundle运行。
OSGi是一个Java框架,其中定义了应用程序即bundle的生命周期模式和服务注册等规范。
OSGi的优点是支持模块动态加载、卸载、启动和停止等行为,尤其适合需要热插拔的模块化大型项目。OpenDaylight 作为一个网络操作系统平台,基于OSGi框架开发可以实现灵活的模块加载和卸载等操作,而无须在对模块进行操作时重启整个控制器,在新版本中,其使用了Karaf容器来运行项目。
Karaf 是Apache旗下的一一个开源项目,是一个基于OSGi的运行环境,提供了一个轻量级的OSGi容器。
基于OpenDaylight控制器开发模块时,还需要使用YANG语言来建模,然后使用YANG Tools生成对应的JavaAPI,并与其他Maven构建的插件代码共同完成服务实现。
特性方面,OpenDaylight 支持丰富的特性,而且在目前版本迭代中依然不断增加特性。
南向协议支持方面,OpenDaylight 支持OpenFlow、NET-CONF、SNMP和PCEP等多种南向协议,所以OpenDaylight可以管理使用不同南向协议的网络。
核心功能部分,OpenDaylight除了支持如拓扑发现等基础的控制器的功能以外,还支持许多新的服务,如VTN (Virtual Tenant Network )、ALTO (Application Layer Traffic Optimization)、DDoS防御及SDNi Wrapper等服务和应用。
值得一提的,SDNi是华为开发并提交给IETF的SDN域间通信的协议草案,目的是实现SDN控制器实例之间的信息交互。
ONOS( Open Network Operating System )
ONOS的架构与普通的SDN控制器架构相似,可划分为南向协议层、南向接口层、分布式核心控制层、北向接口层和应用层,其架构如图3-8所示。
与Ryu等控制器的区别在于: ONOS的核心控制层是一个分布式的架构,支持多实例协同工作。
SDN的数控分离使得集中控制编程自动化成为可能,但是也带来了可拓展性的问题。为支持大规模网络的管理,分布式SDN控制器成为当下SDN控制器设计的主要趋势之一。
分布式不仅提供了更强大的管理能力,具有更好的可拓展性,同时也提供了容灾备份和负载均衡等功能。
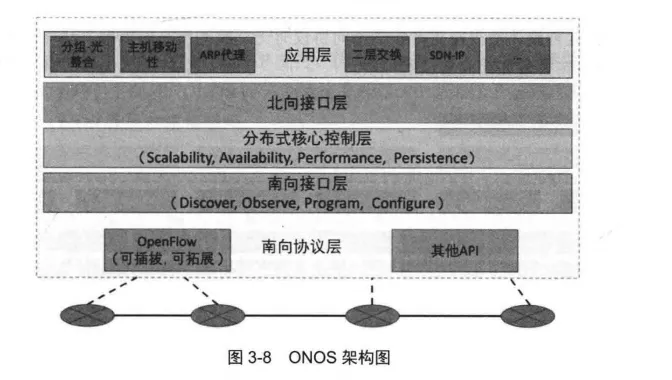
南向协议层包括OpenFlow等多种南向协议的实现,支持以插件形式加载和卸载。
分布式核心层是ONOS架构的关键,主要由拓扑管理、设备管理等多种核心模块组成。
分布式核心层的数据均可以在分布式的实例之间共享。根据数据种类的不同,ONOS同步数据的方式各不相同。目前ONOS使用的是Raft分布式架构,分布式的架构满足了SDN控制平面对可拓展性、可靠性和性能等方面的需求。
北向接口层定义了一系列的北向接口,可供应用程序调用。应用层则是基于ONOS提供的北向接口开发的SDN应用。
特性方面,ONOS支持OpenFlow、NET-CONF 和OVSDB等多种南向协议。
核心功能特性方面,ONOS采用了Floodlight 的优秀核心源码,从而支持链路发现、拓扑管理和网络资源管理等控制器基础功能。
ONOS支持REST API和CLI,用户可以通过REST API和CLI对网络进行编程和操作。
此外,与Ryu和Flodlight等单实例控制器比较,ONOS还具有分布式的特性,具有更好的可拓展性。每个特性由若干个模块组合实现,具体模块示意图如图3-9所示。
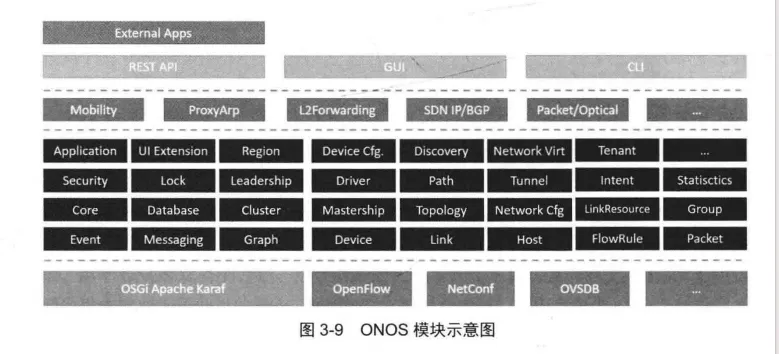
ONOS的代码设计目标包括模块化( Modularity)、可配置(Configurability)、 相关分离/解耦( Separation of Concerm)和协议无关( Protocol Agnosticism)。
模块化体现在ONOS由一系列的子系统模块组成,每个子系统或模块均支持独立编译。
可配置方面得益于使用了Karaf。
此外,Karaf 还允许开发者在运行过程中加载或停止某模块,也允许第三方软件通过RESTAPI等方式安全地获取到ONOS的信息。相关分离是将复杂的控制器分为几个相对独立的子系统,并通过子系统之间相互合作来实现整体控制器的逻辑,从而降低整个系统的复杂度。
“Protocol Agnosticism”直译为“协议不可知”,意译为“协议无关”。这种设计使得在支持新的南向协议时无须改动核心层内容,只需基于协议无关的API就可开发新南向协议的模块。
选择SDN控制器
由“Ashton,Metzler & Associates" 组织发表的Ten Things to Look for in an SDN Controller白皮书介绍了评价SDN控制器的10个方面,如图3-11 所示。
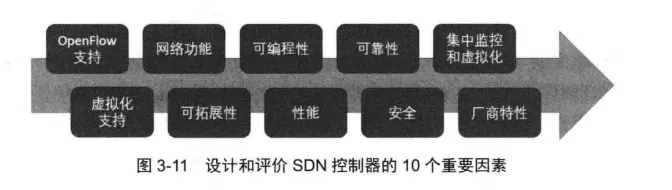
- 支持OpenFlow
- 支持网络虚拟化
- 网络功能
- 可拓展性
- 性能
- 网络可编程
- 可靠性
- 网络安全性
- 集中监控和可视化
- 控制器支持团队
支持OpenFlow
在SDN发展过程中,OpenFlow作为一种主流南向协议获得了业界的广泛认可,绝大多数控制器都支持OpenFlow。但是不同控制器对OpenFlow的支持程度不同,OpenFlow协议本身也存在多个版本,每个版本包含了不同的特性。所以在选择SDN控制器时,首先需要关注其支持的OpenFlow版本,其次要关注其支持的协议特性,比如是否支持IPv6和是否支持组表。
支持网络虚拟化
SDN控制器应支持创建基于策略的、弹性的虚拟网络,它应该支持在拥有全局信息的基础之上,做出最优化的网络资源分配决策,进而提高网络利用率,加速服务部署。支持网络虚拟化是一个优秀SDN控制器所必需的功能。
网络功能
作为一个网络控制器,支持基础的网络功能是最基本的要求。
SDN控制器应该支持基本的交换、路由、安全接入、负载均衡和流量隔离等功能。
可拓展性
SDN的集中控制使得控制器可以掌控全局信息,降低了拓展网络规模的难度,但集中式的控制器性能有限,这也带来了新的网络可拓展性问题。所以,选择SDN控制器时需要考虑控制器在可拓展方面的能力,保证其能管理足够大规模的网络,满足网络需求。一般而言,可管理的交换机数目是衡量控制器可拓展性的重要指标,至少能控制100台
交换机是对控制器的基本要求。
性能
控制器的性能是评价SDN控制器的关键。性能主要指处理网络事件和安装流表项的能力,可以从两个方面进行测量评价:建立流表项的延时和每秒建立流表项的数目,即吞吐量。
目当网络中的交换机产生的新流数目多于控制器所能处理的最大数目时,SDN性能不足的问题就会严重影响网络的效率。
此时,会因为等待建立流表项时间过长而导致连接中断等现象,面对这种情况,应考虑增加控制器的数目,将压力分摊到多个控制器上。
网络可编程
网络可编程是SDN架构最大的优势之一。
在传统网络环境中,部署一项新服 务需要工程师逐跳完成设备配置,但在SDN中就可以通过控制器编程,实现自动化部署。网络工程师逐条部署业务的方式不仅耗时耗力,还无法保证正确性,而且通过这种方式添加的都是静态配置,无法根据实际情况快速做出调整。为了实现更智能的网络管理,SDN控制器需要拥有网络可编程能力,从而实现(近似)实时、动态的网络管理和配置。
可靠性
可靠性主要分为数据平面网络可靠性和控制平面可靠性。
作为网络的管控中心,可靠性是最基本也是最重要的要求。
数据平面网络可靠性方面主要体现在当转发路径不可达时,控制器应能快速计算出备份路径或逃生路径,从而保障数据平面网络联通性的基本要求。为保障数据平面网络可靠性,需支持多路径传输的热备份等措施。为此,控制器应支持**VRRP (Virtual Router Redundancy Protocol,虚拟路由器冗余协议)**等协议或其他多路径算法。
另一方面,为了提高控制平面的可靠性,不仅要提高控制器本身的稳定性,还有使用集群等手段进行热备份或冷备份,保障数据安全,提高控制平面网络的可靠性。
网络安全性
为了保障网络的安全性,SDN控制器必须支持企业级别的授权和认证。对于控制流量等重要的流量,网络管理人员应该对其进行监控,保证安全。另一方面,SDN控制器应该支持网络安全功能,如防火墙和ACL等功能应用。SDN控制器也应有能力对数据包进行过滤,部署动态的ACL等功能,从而提高网络的安全性。
集中监控和可视化
对网络进行实时监控能为网络正常运行提供保障,所以SDN控制器需要支持网络监控功能。
另外,凭借全局网络信息,SDN控制器可以对网络进行可视化展示,可以实现快速的故障定位。
SDN控制器应支持使用通用的协议来对网络进行监控和可视化展示,并支持通过REST API等接口来获取网络信息。支持可视化的网络监控是对SDN控制器最基本的要求之一。
控制器支持团队
面对目前还未稳定的SDN发展状况和竞争局面,选择一个控制器
不仅仅要考虑技术方面的因素,还需要考虑控制器支撑团队的实力。在选择和评价一款SDN控制器是否有更好的发展前景时,需要考虑其支撑团队对SDN的投入,包括是否愿意长时间对该控制器投入研发力量,是否有实力将它发展成未来的主流控制器等内容。
若支撑团队不能及时跟上SDN的发展,无法及时更新SDN控制器的特性,那么这样的控制器将会丧失竞争力。
选择正确的控制器
- 开源和商业
- 应用生态和成熟的向北接口
- 基于应用场景选择
- 控制器的可靠性和兼容性
- 与云管理平台产品结合
- 稳定的API己清晰的发展路线
开源和商业
对于部署SDN的企业而言,选择开源控制器还是商业控制器是一个很重要的决定。
选择开源的好处在于可以解除厂商的锁定,降低工程师的培养成本。
而选择商业的好处在于更多的私有特性及更好的技术支持。
不过目前为止,南向接口协议数目众多,控制器厂商还无法在南向协议上进行锁定。
对于SDN学习者而言,只能选择开源控制器。
在开源控制器中,根据自身对语言的偏好,以及研究领域对SDN控制器的需求选择合适的控制器才是最好的选择,而不应该选择最流行的控制器。
比如,有的读者喜欢Python语言的简洁风格,可以选择Ryu等Python编写的控制器,而喜欢Java语言的读者,则可以选择OpenDaylight和ONOS。
应用生态和成熟的向北接口
优秀的控制器应该拥有完整的应用生态系统,便于初学者学习及企业部署,同时,成熟的北向接口也是控制器稳定发展的前提。
具有成熟北向接口的控制器可以给开发者提供许多帮助。若某个控制器的应用不丰富,北向接口不完善,那么可以认定这个控制器没有发展前景。
基于应用场景选择
根据应用场景需求挑选控制器而非选择最流行的控制器。
比如网络规模很小,目的是科研验证,则可以选择轻量级的Ryu,从而降低开发成本,快速验证科学研究;
而如果目的是工程部署则需要选择更大型的控制器如OpenDaylight和ONOS。
但是,商业部署也分为许多不同的场景,对应着许多不同的控制器,比如某控制器专门为WAN设计,可能在数据中心中运行会表现欠佳。
基于应用场景需求才能选择最合适的控制器,如此做出的选择才是最佳的决策。
控制器的可靠性和兼容性
由于控制器是SDN的关键,所以在选择控制器时最应该考虑它的可靠性。
在选择控制器时,可以结合其被使用的频率、部署的案例数目及它的案例运行时间等情况综合考虑,以确保它在生产网络中的可靠性和稳定性。
在对比两个控制器相似的特性时,需重点考虑它们的平稳运行时长,从而判断它们的可靠性。
此外,在选择控制器之前,需要确保控制器能兼容现有的网络设备,以及不会因为不兼容导致网络无法运行。
与云管理平台产品结合
几乎所有的商业控制器及开源控制器均支持数据中心场景下与OpenStack集成。
在云计算快速发展、数据中心越来越多的情况下,SDN控制器非常有必要和OpenStack等云管理平台结合。
若用户需要在数据中心部署SDN,那么需要确认所选的SDN控制器对云管理平台的支持,以确保它可以无缝接入到云管理平台。
稳定的API己清晰的发展路线
稳定的API是保障解决方案在控制器更新换代时可以平滑过渡的关键因素。
若控制器在更新换代的过程中,新版本的API与早期的API不同,那么使用早期版本API部署的网络解决方案很难被新版本控制器支持。
所以,在选择控制器时需要了解其API开发的计划和发展路线(Roadmap),确保它的API接口稳定,以减少重新部署解决方案的风险。
SDN数据平面
在SDN架构中,控制平面是网络的大脑,控制着数据平面的行为,而数据平面是执行网络数据包处理的实体。
传统设备的数据平面的网络处理行为都是协议相关的。
传统网络设备的功能模块在生产时就已经固定,只支持有限的用户配置,而不支持用户进行编程自定义,所以产品升级困难。比如,包解析模块只能对数据包的特定协议进行解析。
SDN的数控分离设计,解决了控制平面和数据平面升级依赖的问题,也为网络提供了更多的可编程能力。
而本质上,决定网络编程能力的因素在于数据平面的可编程。
只有数据平面提供足够的可编程能力,控制平面才能通过南向接口来对网络进行更灵活的编程控制。
通用的可编程数据平面支持网络用户通过软件编程的方式任意定义数据平面的功能,包括数据包的解析和数据包的处理等功能,可以实现真正意义上的软件定义网络。
SDN通用可编程数据平面架构如图4-2所示。
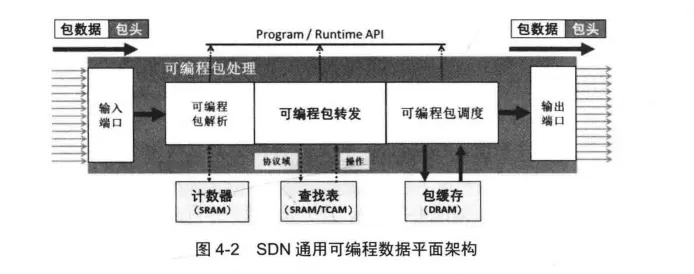
此外,为了提供更好的可拓展性,通用可编程数据平面设备中所有的网络处理模块,包括包解析器(Parser)、包转发(Packet Forwarding)和包调度( Packet Scheduling )等模块都是可编程重配置或者是协议无关的,都具备足够的可编程能力。
2008年,斯坦福大学The McKeown Group的Martin Casado 等人在论文Rethinking Packet Forwarding Hardware中首次讨论了现有路由器和交换机中网络转发平面的不足,
他们认为理想的网络转发模型应该具备以下三个条件:
-
清晰的软硬件接口(Clean interface between hardware and software)。 清晰的软硬件接口可以支持软硬件体系结构各自独立地演进。
以x86指令集为例,处理器硬件和操作系统可以独立地升级。理想的网络转发模型应该与网络协议无关,支持根据软件编程实现所有的协议功能,甚至支持新的网络协议。 -
简洁的硬件架构(Hardwaresimplicity)。
这里的简洁是指网络转发模型的硬件架构像通用处理器的架构一样,支持模块化的可扩展能力,在同样的硬件体系结构下,能够通过增加处理器内核或子模块的数量来提升系统性能。 -
灵活有效的功能实现(Flexible and efficient functionality)。
相比传统网络转发平面的功能堆砌,网络转发模型能够高性能且低成本地实现大多数的网络功能,同时能够快速地添加新功能。
The McKeown Group在此基础上定义了一种可编程通用转发抽象模型(General Forwarding Abstraction): OpenFlow Switch。
在SDN通用可编程数据平面的发展过程中,OpenFlowSwitch通用转发模型是现在通用可编程数据平面中的代表。
目前为止,业界主流的SDN硬件交换机都实现了对OpenFlow Switch通用转发模型的支持,包括业界使用最多的开源软件交换机Open vSwitch。(可能数据已经过时)
但是OpenFlow Switch只是一种通用可编程转发抽象模型的尝试,其还有很多地方没有达到以上对通用可编程转发抽象模型的要求,比如其不支持协议无关转发,也不支持对数据包解析逻辑进行编程。
通用可编程转发模型
传统路由器和交换机的转发处理都是协议相关的,每个模块都是为了实现特定的网络协议而设计的,一旦设计完成就只能处理固定格式的网络数据包,无法根据用户需求来支持新的网络协议,如图4-3 所示。
其中,L2表模块只能完成MAC层的地址学习和查找处理,而L3表模块只能完成IP层的学习和查找处理。
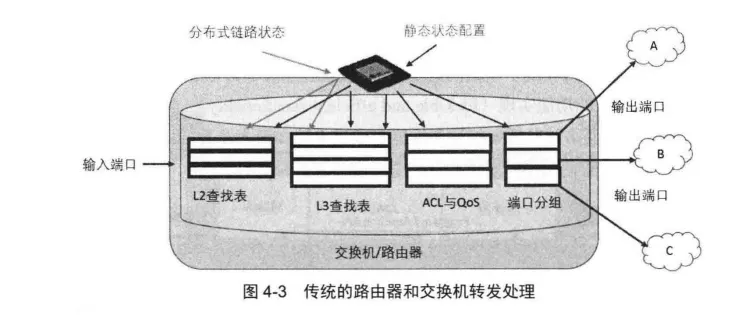
相比传统的转发平面,OpenFlowSwitch将网络数据转发处理抽象成通用的Match-Action过程,同时对网络系统中的各种查找表进行了通用化处理,抽象成一种新的通用流表转发模型结构,如图4-4 所示。
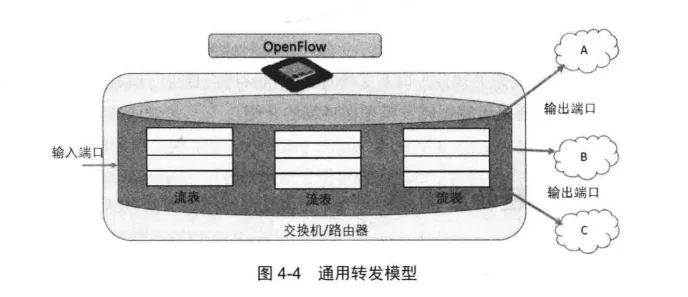
其中每个流表都可以实现用户定义的网络处理功能,从而实现可编程的网络数据转发处理。这种新的通用转发模型有如下特征:
- 转发行为由控制平面指定( Behavior specified by control plane )
- 由基础转发原语组成( Built from basic set of forwarding primitives )
- 支撑高性能和低功耗( Streamlined for speed and low-power)
- 避免厂商锁定控制程序(Control program not vendor-specific)
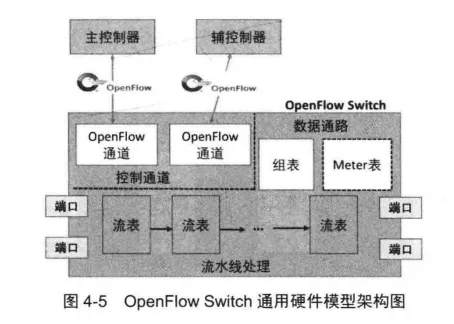
OpenFlow Switch通用转发模型主要包括“通用硬件模型”和“通用处理指令”两部分。通用硬件模型由一组网络通用硬件子模型组成。通用处理指令包含了一组用户可编程的网络处理操作和控制指令。
通用硬件模型
OpenFlow Switch通用硬件模型的架构如图4-5所示。它的网络数据处理流程为:
首先,数据包从某个端口进入通用模型,通用模型中的协议解析模块完成对数据包头部分的分析,然后根据分析结果选择对应的流表进行处理。
在流表内部,解析出来的数据包内容会与每个流表项进行比较。假如数据包匹配到了流表的一条表项,则通用模型需要对该数据包执行表项中规定的处理操作,反之,则会按照某种特定指令来处理,比如丢弃或转发给控制器。
OpenFlow Switch 的网络通用处理指令分为操作指令、跳转指令和专用指令三种类
型。
操作指令通常是对网络数据包的具体操作,比如转发数据包、修改数据包,以及组表处理和Meter表处理;
跳转指令实现网络数据包在多个流表之间的跳转操作;
专用指令实现某种特定的网络数据流处理。
在网络通用硬件模型中完成数据包处理之后,会将数据包从某个指定端口发送出去。
在OpenFlow Switch通用硬件模型中,对每个数据包的处理取决于其包头标识域在匹配表中的搜索结果,这个搜索结果会说明需要对数据包做何种操作。
不同类型的Match-Action处理表组成不同的网络通用硬件子模型,比如流表、组表和Meter表。
流水线处理
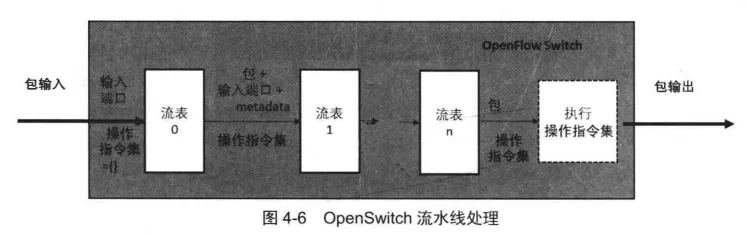
OpenFlow Switch通用硬件模型最重要的一个概念就是1.1版本提出的“多级流表”,其支持网络数据包在多个流表之间进行处理,如图4-6 所示。
相比1.0版本的“单流表”概念,“多级流表”具备两方面的优势。
首先是因为现有的交换芯片内部通常有多个查找表,比如二层转发表、三层路由表和访问接入控制查找表等,“多级流表”概念使得这些芯片更容易支持OpenFlow Switch多级流表,资源利用率也变得更高;
其次,很多网络应用会根据不同包头域组合,对数据包进行关联处理。如果只在单个流表中实现,将会造成流表的资源浪费;
而通过多级流表的流表跳转指令实现不同处理之间的逻辑关系,可以让OpenFlow Switch模型具备更强的适配能力,而且节省流表空间。比如匹配域数目为N+M,假设每个匹配域可能值的总数目都是x,那么为了满足所有可能的流表匹配,需要条流表项,而如果采用二级流表,第一个流表的匹配域数目为N,第二个流表的匹配域数目为M,则只需要条流表就可以支持所有流的匹配。同理,流表数目越多,压缩效果就越明显,流表项支持的编程逻辑也更复杂,而流表的设计逻辑也更复杂。
在支持多级流表的OpenFlow Switch通用硬件模型中,每个数据包在进入流水线之前,将被分配一个对应的操作指令集(Action Set,网络数据操作指令集合)。
然后,数据包进入第0个流表开始处理,通用硬件模型将把数据包协议内容与每个表项进行匹配查找。
完成查找过程之后,通用硬件模型会将流表项中定义的操作指令写进操作指令集中,或者传输给下一个流表,或者在指令执行模块完成对数据包的操作处理。
此外,多个流表之间也可以通过一个Metadata来交互信息,这个Metadata信息可以添加到下一个流表的匹配域中,也可以直接写进某个流表项。
OpenFlow Switch还定义了一个跳转控制指令Instruction, 用来控制网络数据在流表之间的流水线处理。
流表
在理解流表抽象子模型之前,需要先了解网络设备中的转发表概念。
网络设备中的转发表是一种“键-值(Key-Value)”查找表,通过表内容匹配来返回匹配成功的操作数据。
转发表的键值是各种网络协议的字段,比如源MAC地址和目的MAC地址等。键值匹配成功时返回的值是对数据包的操作指令,比如将其转发到对应的端口等操作。
流表就是一种这样的转发表。
OpenFlowSwitch采用Flow(数据流/流)的概念来描述具备相同特征的网络数据包集合。我们每天都在产生Flow, 比如访问网页,就会制造一系列的数据包,就会产生一些数据流,也就是Flow。
区分Flow的特征有很多,比如业务类型和通信地址等。
所以,上网浏览网页和浏览视频两种不同业务的数据流可以根据业务类型不同分为两种Flow,你和邻居上网的数据流就可以根据通信地址的不同而分为两种Flow。
为完成Flow的处理,OpenFlow Switch定义了Flow Entry (流表项)来处理对应的数据流,这些流表项均存储在流表中。
所以,Flow是OpenFlowSwitch通用硬件模型处理的基本对象之一。
OpenFlow Switch引入Flow的概念,使得网络用户可以在会话级、应用级和用户级等更细颗粒度的层面上部署网络策略。
每个流表由多条流表项组成,用户通过对这些表项进行编程来区分Flow, 同时定义对应Flow的处理指令。每个流表项对应一个特定的Flow,其结构通常由六部分组成,如图4-7所示。
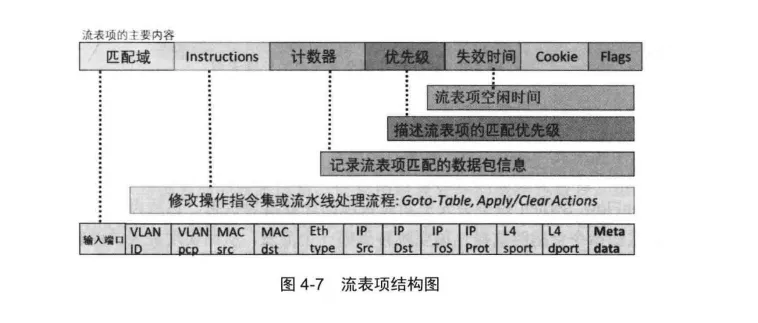
流表项的匹配域用来与每个数据包的指定包头标识集合进行比较,包括输入端口、包头标识域和Metadata三部分。
Instructions 用来指定该Flow中数据包的跳转操作,同时也包括对流表项的操作指令集的操作。
流表项的计数器(Counters) 用来实时统计与流表项匹配成功的数据包数目等信息,这些统计信息是网络用户分析流量的关键信息。
流表项的优先级(Priority) 用来说明该流表项的匹配优先级,当数据包与多条流表项匹配成功时,需要按照优先级来选择出一条流表项,并执行该表项的动作。
流表项的失效时间(Timeouts) 用来指定该流表项的失效时间,包括硬超时( Hard_Timeout) 和软超时(Idle_ Timeout) 两种设置。如果流表项的生存时间超过硬生存时间,或者在软生存时间内没有匹配到数据包,流表项中的内容将会被清空。
Flow的每个网络数据包在单个流表中的处理流程如图4-8所示。
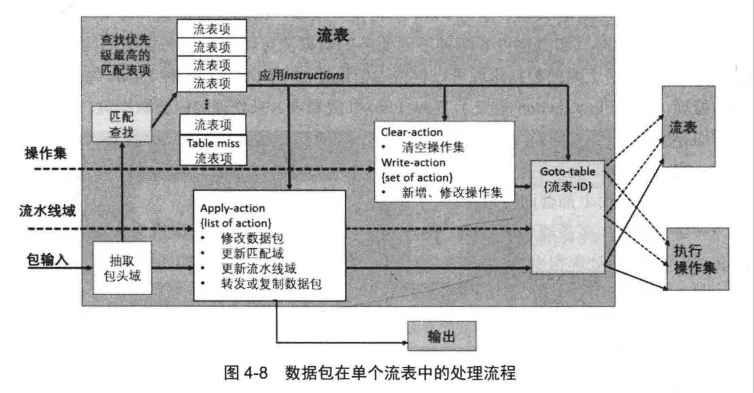
OpenFlow Switch 模型需要先从网络数据包中提取出待匹配的网络数据包协议字段组合,再加上来自上一个流表的Metadata信息共同组成一个待匹配域。
然后,将这个待匹配域跟当前流表的所有流表项进行比较,如果有唯一的流表项与数据包的匹配域匹配,这时,OpenFlowSwitch模型会先更新流表项的计数器等状态,然后再执行该流表项中的指令,这些指令会指明数据包需要跳转到哪一个流表,从而实现流表的跳转。
需要注意的是,流表跳转指令只能控制数据包沿着流水线的顺序方向处理,不能回退到之前的流表。
当该流表项中没有指定跳转指令时,流水线处理就会停止跳转,然后对数据包执行具体的操作,比如修改包头域和转发数据包等。
所以,流水线中的最后一个流表不会包含流表跳转指令,从而强制停止流水线处理。
组表
组表也是一种转发表类型的抽象子模型,其具备给一组端口定义某种指定操作的抽象能力,从而为组播、负载均衡、重定向及聚类操作等网络功能提供更加便捷的实现方式。
每个组表由多条组表项组成,用户通过编程这些表项来定义这组端口和要执行的操作。
通过在流表项中使用Group动作可以将Flow的数据包指向某个组操作,从而执行组表中的动作集合。
组表的存在使得OpenFlow Switch通用转发模型能实现更多、更加灵活的转发策略。组表的表项通常由四部分组成,如图4-9所示。
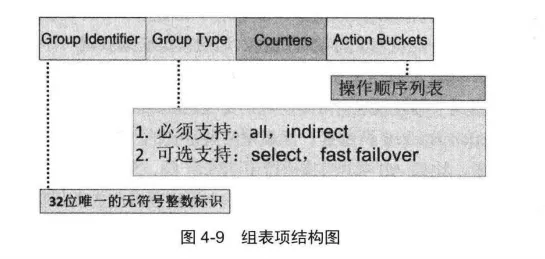
组表项的Group Identifer用来唯一标识这个表项, 其为一个32位的整数,这也是组表与流表结构不同的地方之一。
组表项的计数器(Counters) 与流表中的功能类似,用来实时统计与该表项的状态信息,比如由组表处理的数据包数目。
组表项的**操作桶(Action Buckets)**用来存储多个Action Bucket,每个Action Bucket包含一个数据包操作指令集。
组表项的Group Type域用来指定该组表项的类型,目前OpenFlow Switch通用硬件模型定义了如下四种组表项类型。
-
全选择类型(AIl), 这种组表项会执行Action Buckets 中所有Action Bucket中的操作动作集,可用来实现网络中的组播和广播功能。
对应Flow的数据包会被复制到每个Action Bucket, 然后进行处理。如果某个Action Bucket将数据包直接转发给输入端口,就不会复制这个数据包。 -
选择类型(Select), 这种表项只选择执行一个Action Bucket 的动作集,通常用交换机自己的算法来选择这个Action Bucket,比如根据用户配置元组的哈希算法,或者简单的轮询算法。
这个选择算法需要的所有配置信息和状态都来自通用模型外部,即需要用户在控制器端进行软件编程。当某个ActionBucket选择的端口物理连接断开时,转发模型可以选择其余的端口,比如那些包含转发操作的激活端口,而不是丢弃发给该端口的数据包。采用Select类型的组表可以减少链路或交换机故障对网络业务的影响,也经常被用于流量的网络负载均衡(Network Load Balancing)。 -
间接类型(Indirect),这种组表项只能支持一个Action Bucket。用来实现多个流表项或多个组表项指向单一组表ID的情况,支持快速、高效的汇聚功能。
这种组表项是相对简单的一种类型,通常此类型的组表项数目要比其他类型的组表项多。 -
快速恢复类型(Fast Failover), 这种表项只执行第一个激活的Action Bucket。
这种组表类型能让转发模型自己调整转发操作,不需要每次都请求控制器。Fast Failover类型组表多用于容灾备份场景,当前操作由于故障无法执行时,切换到备份的动作组,从而保障业务不中断。但是为支持这种组表,通用模型必须实现一个“活跃度机制”,用于实现Action Bucket的排序。当没有激活的Action Bucket时,数据包会被丢弃。组表子模型也是一种转发表,只是表项的定义与流表的内容不同,其表项主要包括组表项类型和Action Buckets两部分。
组表项类型定义的四种类型,分别抽象了四种不同的网络应用场景,比如All类型主要用于组播和广播,Select 类型主要用于实现轮询的ECMP或链路聚合等。Action Buckets定义每个组表项对应的动作集。
Meter表
Meter表是第三种转发表类型的抽象子模型,其使得OpenFlowSwitch模型具备测量Flow的能力,可用来实现速率控制等简单的QoS服务,也可以用来实现相对复杂的QoS服务。
每个Meter表由多条计量表项(Meter Entry)组成,这些计量表项可以用来测量和控制某个Flow的数据包传输速率,其结构通常由三部分组成,如图4-10所示。
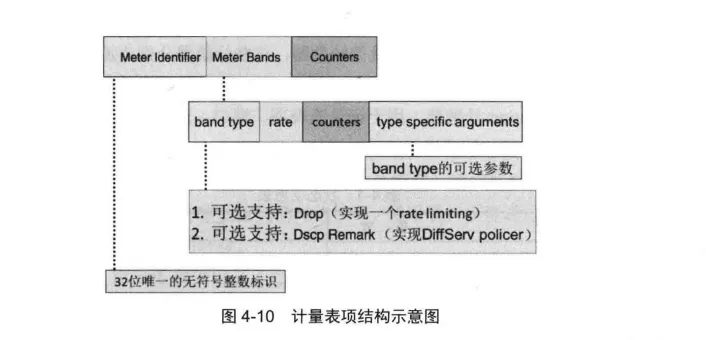
网络用户可以在流表项中指定一个对应的计量表项,用来完成对这个Flow的测量和控制。
计量表项的计量标识( Meter Identifier) 用来唯一标识这个计量表项,也是一个32位的无符号整数。
计量表项的计数器(Counters) 与流表中的功能类似,用来实时统计与该表项相关的状态信息,如该表项处理的数据包数目等信息。
**计量表项的计量带(Meter Bands)**用来定义该表项对应的一组操作,在实际处理过程中,这些计量带的操作是没有优先级顺序的。
每个计量带指定一个网络数据流的传输速率阀值,也就是上图中的速率域。
其中的Band Type定义了一种对应的包处理方式,通常只有网络数据流的当前流量速率超过这个速率阀值时,才会执行Band Type中的指定操作。每个计量带Band类型中的操作包括丢弃(Drop)和修改DSCP的Remark,其中丢弃操作用于实现对应Flow的速率控制,DSCP Remark操作用于实现一个简单的DiffServ。
计量表抽象子模型用速率域中指定的速率阈值来唯一标识这个计量带。计量带的计数器用来实时统计与该计量带的相关状态信息,比如该计量带已完成处理的数据包数目。
**计量带的类型参数(Type SpecificArguments)**是一个保留域,用户可以自定义这个可选参数。
Meter表子模型是一种转发表,其计量表项主要包括计量ID和计量带两部分。
计量ID定义需要测量的Flow,计量带定义如何对这个Flow进行测量。
状态信息表
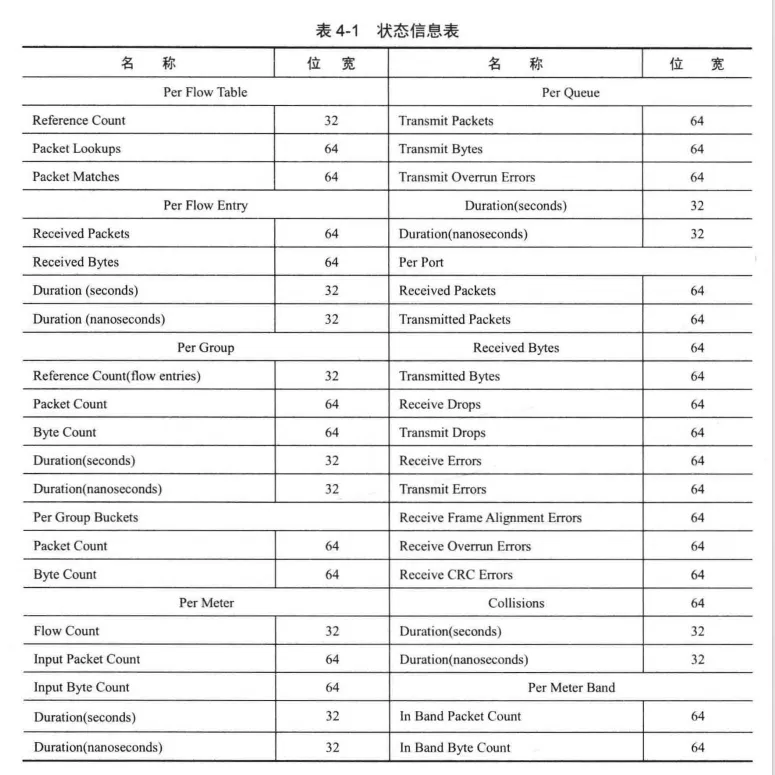
前面三个小节讨论了OpenFlow Switch 模型的三种表抽象子模型,接下来讨论OpenFlow Switch模型的另一种抽象子模型:计数器。
这些计数器组合起来就构成了一个基于Flow的网络状态信息表,对特定Flow的数据包进行统计和记录。
OpenFlow Switch 模型定义了大量的计数器,这些计数器分别由流表、流表项、端口、队列、Group、Group Bucket (组操作桶)、Meter和计量带维护着。
其中有一种特殊的计数器————Duration 计数器,用于记录流表项、端口、队列、Group 和Meter的存活时间,通常按照纳秒的精度进行统计。详情见表4-1。
在具体实现中,OpenFlow Switch 模型中的计数器可以用软件实现,也可以用硬件实现。
端口
端口子模型是表抽象子模型和计数器子模型之外的第三种抽象子模型。
对于网络设备而言,这是一种常见的抽象模型。端口是指在OpenFlow Switch模型和其他网络设备之间传输数据包的网络接口,通用硬件模型通过端口互相连接在一起,此处的连接强调逻辑上的连接。
OpenFlow Switch模型定义了物理端口(Physical Port)、逻辑端口(Logical Port)和保留端口(Reserved Port)三种端口类型。
所有物理端口、逻辑端口和保留端口中的本地(Local)类型统称为标准端口,只有这些标准端口才能用作网络数据包的输入和输出端口,才能在组表中使用,才能拥有端口计数器、端口状态和配置信息。
端口模型中的物理端口是指物理网络中的真实网络接口,与网络设备中的物理接口一一对应。逻辑端口与真实网络接口无直接对应关系,是一种抽象的逻辑端口,通常用来描述链路聚合组、隧道和回环接口等逻辑概念。
保留端口是OpenFlow Switch模型中预留的虚拟端口类型。
端口模型中的不同类型的保留端口介绍见表4-2。


通用处理指令
计算机程序要控制硬件工作,必须使用硬件所能识别的语言,这些语言及其用法统称为指令集。
指令集在程序员和处理器之间提供了–个抽象层,程序员编写软件时只需要知道有哪些指令,以及如何使用即可,无须关心处理器如何实现。
大多数计算机指令集都会包含三种类型的指令:存储器访问指令、数据运算指令和流控制指令。
与计算机指令集类似,OpenFlow Switch 的通用处理指令包括“网络处理控制指令Instructions”,“网络数据操作指令Actions” 和“专用网络处理指令”三部分。
网络处理控制指令Instructions
OpenFlowSwitch定义的第一种网络通用处理指令是基于Flow的网络处理流程控制指令Instructions,这种指令可以控制数据包在通用硬件模型流水线上的处理流程。
控制指令有两种类型:
第一类是对Flow数据包的操作指令集进行写入、应用或者删除等修改操作指令,比如写操作指令( Write-Actions)和应用操作指令(Apply-Actions);
第二类是指定Flow数据包在多个表中的处理顺序的跳转指令,比如Goto-Table指令等。
OpenFlow Switch网络通用指令包含的控制指令类型如表4-3所示。

每个流表项中可以包括多个控制指令,这些控制指令组合成一个对应的指令集合。
在实际的指令执行过程中,需要按照上表中的顺序来执行指令集合中的控制指令,比如应用操作指令在清除操作指令之前执行,清除操作指令需要在写操作指令之前执行,写操作指令需要在写Metadata指令之前执行,Goto-Table 指令应在最后执行。
对比计算机指令集中的三种类型,OpenFlow Switch模型中定义的流水线控制指令Instructions与处理器中的流控制指令类似,用来控制网络数据处理的流程。
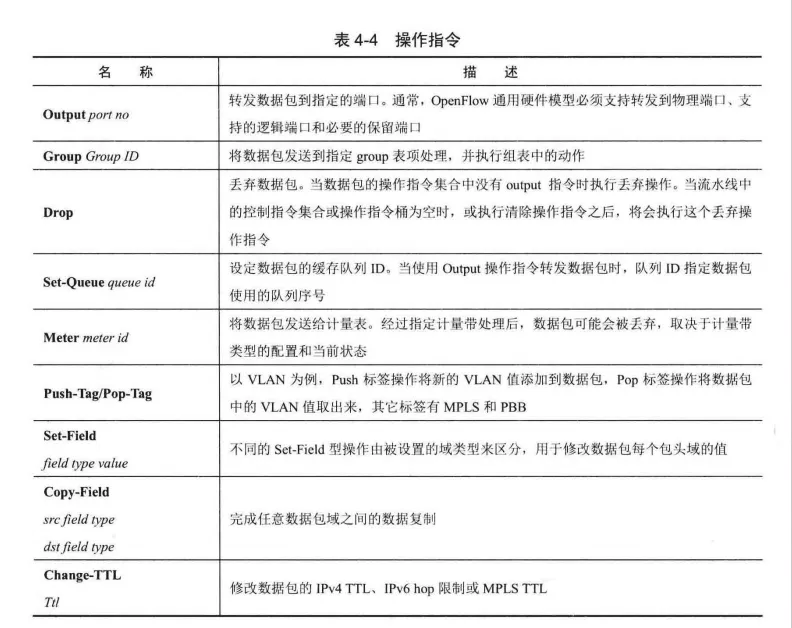
操作指令
OpenFlowSwitch定义的第二种网络通用指令是基于Flow的网络处理操作指令Actions,这种指令完成对数据包的丢弃、复制、转发和修改等操作。
每一个数据包在进入流水线时都会被分配一个Action Set, 用于保存处理数据的动作,其集合中同一类型的动作最多只能有一个。
此外,OpenFlow Switch还定义了一个Action List 概念,其用于存储一组动作列表,同种类型的动作数目不受限制。
OpenFlow Switch网络通用指令包含的操作指令类型如表4-4所示。
当数据包到达OpenFlowSwitch通用硬件模型时,OpenFlow Switch模型会给数据包分配空的操作指令集。
当数据包在流表中进行处理时,表项中的控制指令完成对操作指令集合的指令添加、更新和删除等操作。
默认情况下,操作指令集中命令的执行顺序如图4-11所示,而Action List中的命令执行顺序则是按照列表中的动作先后顺序执行。
同样的,组表项中Action Bucket的默认操作指令执行顺序也是按照图4-11所示来进行。

对比计算机指令集中的三种类型,OpenFlow Switch模型中定义的操作指令Actions与处理器中的逻辑运算指令类似,用来描述对数据包执行具体的操作。
专用指令
OpenFlow Switch定义的第三种网络通用指令是基于Flow的专用指令。
这种专用指令通过一条指令实现某种特定的网络处理功能。在OpenFlow Switch模型中,Table-miss是专用指令的代表。
Table-miss指令定义了在流表中匹配不成功时处理网络数据包的行为,可通过在每个流表中实现一个Table-miss专用表项来实现Table-miss指令。对于Table-miss表项而言,不仅要省略所有匹配域,还要将优先级域设置成零,即最低优先级。所以,任何数据包在匹配不到正常流表项的情况下,都可以和Table-miss流表项匹配成功。
当一个网络数据包进入一个流表,却没有匹配到任何流表项时,就会默认执行Table-miss表项定义的指令,比如丢弃该数据包,转发给控制器或转发给另一个流表。
从控制器的角度来看,这个专用流表项与其他流表项完全相同,也可以被控制器动态控制,也有失效时间。
综上所述,OpenFlow Switch模型定义了类似计算机指令的三种网络处理通用指令:
控制指令Instructions 用来控制基于Flow的网络数据包处理流程;
操作指令Actions用来实现对这些网络数据包的具体操作处理,比如转发、丟弃和修改包头协议域;
专用指令通过专用流表项实现一种特定的网络数据包处理,比如典型的Table-miss指令。
探索通用可编程数据平面
相比传统网络数据平面,通用可编程数据平面让网络用户可以自定义数据包的完整处理流程,实现理想的协议无关网络数据处理。而当下的OpenFlow模型还无法成为一种完全的通用可编程数据转发模型,还无法实现协议无关的转发。只有实现了真正的通用可编程数据平面,才会真正释放网络的可编程能力,从而逐步实现网络的软件化和程序化。
对于网络用户和网络服务供应商,通用可编程数据平面使得他们可以快速地开发新网络功能及部署新网络服务。网络用户可以从软件产业过去几十年已发展成熟的软件编程理论、软件工程实践和工具中受益。计算机软件工程师也能够很容易对网络数据平面设备进行编程、测试和调试,以一个完全可编程的方式来管理整个网络。
对于网络芯片供应商,通用可编程数据平面使他们能专注于设计及改进那些可重用的数据包处理架构和基本模块,而不是纠缠特定协议里错综复杂的细节和异常行为。而且,一旦证明这些架构和基本模块可行,供应商就可以在多代交换芯片的设计中重复使用它们,不必为客户不断产生的新需求而反复修改。
对于网络研究人员,通用可编程数据平面为他们验证新想法提供了新的契机。OpenFlow数据平面设备早期被广泛用于网络科研领域这一事实也证明 了这一点。网络研究人员基于通用可编程数据平面可以快速搭建满足新实验需求的网络系统,不需要等待设备厂商的产品升级。
从OpenFlow Switch通用转发模型诞生至今,学术界和产业界在通用可编程数据平面领域做了很多努力,持续推动了SDN数据平面的发展。其中典型的通用可编程数据平面设计思路是The McKeown Group 的可编程协议无关交换机架构PISA(Protocol-Independent Switch Architecture),如图4-12所示。
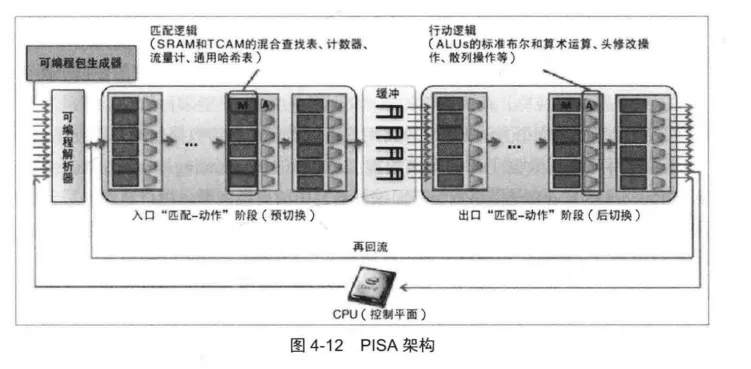
PISA是在2013年的RMT (Reconfigurable Match Tables)架构中基础上发展起来的一种新的SDN数据平面。到达PISA系统的数据包先由可编程解析器解析,再通过入口侧一系列的Match-Action阶段,然后经由队列系统交换,由出口Match-Action阶段再次处理,最后重新组装发送到输出端口。
其中可编程协议解析器模型是Glen Gibb等在2013年提出的一种新的通用抽象模型,实现了协议无关的网络数据包协议解析处理,改进了OpenFlow Switch在支持新网络协议方面的不足。可编程的Match-Action模型实现了协议无关的网络数据转发处理,包括匹配逻辑和行动逻辑两部分。匹配逻辑是通过静态随机存储器(SRAM)和三态内容寻址存储器(TCAM)的混合查找表,以及计数器、流量统计表和通用哈希表组合实现的。
行动逻辑是通过一组ALU标准布尔和算数运算单元、数据包头修改操作和散列操作组合实现的。
PISA还提供了一条回流路径使–些特殊数据包能够被多次反馈到解析器和转发处理流水线。PISA实现了一个可编程数据包生成器,使控制平面可以将频繁或周期性的数据包生成操作交给数据包生成器来完成。
可以看出,PISA通用可编程数据平面在可编程协议解析处理和可编程数据包处理操作两个方面进行了扩展。但是中间数据包调度部分还是采用传统的设计思路,不支持用户可编程的数据包队列管理和调度处理。
Sivaraman等在2015年提出了一种通用可编程包调度处理模型,实现了用户可编程的包调度处理,改进了PISA 在数据包调度处理可编程性方面的不足。
但是,相比通用计算数据平面,PISA在可编程生态上还有不足。通用计算数据平面就是通用处理器,就是我们所熟悉的如何在通用处理器上编程、基于高级编程语言描述具体的应用,以及编译这些程序并在通用处理器上运行。
计算机领域的数据平面可编程生态系统已经非常成熟,而在网络领域里,这样的故事才刚刚开始。
网络数据平面编程语言的出现,使得用户可以自定义网络数据包的处理流程,进一步提升了通用可编程数据平面的可编程能力。
P4 ( Programming Protocol-Independent Packet Processors)语言是网络数据平面编程语言中的典型例子。用户通过编写一段P4程序来定义数据包的处理流程,然后利用P4编译器将这段程序翻译成指定网络数据平面的配置信息,从而实现用户可编程的网络数据处理,如图4-13所示。
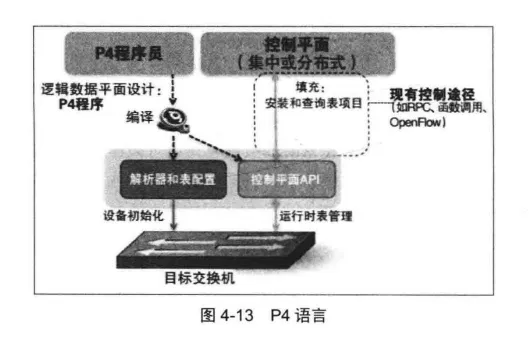
P4数据平面编程语言框架是否能成为–种成功的通用可编程数据平面,其关键在于P4语言的建模能力和P4开发工具的完善程度。P4语言的建模能力依赖于语言本身的发展和功能库的完善。
每个P4程序包含Header、 Parser、 Table、 Action 和Control Programs五部分。P4联盟创建了一个开源社区,发布了广受支持的1.0.2版本和最新的1.1.0版本语言规范,也维护了一组P4程序案例。
现有的开源P4开发工具主要包括P4编译器、P4交换机参考模型和测试框架。P4编译器需要从P4程序的Header和Parser部分导出数据平面解析器的配置信息,从Table、Action和Control Programs中导出Match-Action表中的配置信息和所有依赖关系。同时,编译器还需要考虑目标数据平面硬件的功能和特性,尽可能支持更多的目标硬件。
需要注意的是,通过编译P4程序,不仅可以生成数据平面设备的配置信息,还可以生成运行API,来实现控制平面与数据平面之间的交互。
在这些开发工具的支持下,用户可以很容易地编写和编译自己的P4程序,使用参考模型来运行和调试程序。
除此之外,在OpenFlowSwitch通用转发模型的基础上,研究人员尝试建立更加通用的网络数据处理抽象模型。
华为美国研究所的宋浩宇等提出了协议无关转发(Protocol Oblivious Forwarding, POF) 框架,通过对网络转发处理行为进行再次抽象,实现协议无关转发处理。
具体来说,对任意报文,其报文解析和匹配域读取都可以抽象为在报文特定位置读取特定长度比特串{offset,length},转发面仅需要知道偏移量和长度就可以完成处理。同样,对于报文的处理也可以抽象为在报文特定位置的比特串的插入、删除、拷贝和修改等操作。
在POF架构中,POF交换机并没有协议的概念,它仅在POF控制器的指导下通过{offset, length}来定位待匹配的数据,从而完成网络数据转发处理。
针对OpenFlow Switch不支持描述有状态网络处理的问题,罗马杜维嘉大学的Giuseppe Bianchi等在OpenFlow Switch基础上增加了新的抽象子模型State Table,创建了支持有状态网络处理的新通用数据平面模型OpenState。明尼苏达大学的Hesham Mekky等提出的应用感知SDN架构,在OpenFlowSwitch基础上增加了新的应用Table子模块,增强了数据平面支持有状态网络处理的抽象能力。普林斯顿大学研究团队提出了一种新的网络数据处理原语FAST ( Flow-level State Transitions) ,使得用户可以通过SDN控制器对数据平面设备的有状态处理流程进行编程。这些新的研究思路都对OpenFlow Switch通用转发模型的抽象能力做了进一步扩展。
此外,日本的NEC公司在OpenFlowSwitch通用转发模型基础上设计网络领域的专用指令集处理器(ASIP, Application Specifc Instruction Set Processor)。
在网络数据平面发展过程中,网络处理器(NP, Network Processor)与通用可编程数据平面非常相似。
网络处理器是一种可编程的网络处理硬件,它结合了RISC处理器的低成本、灵活性及定制芯片(ASIC) 的高性能。网络处理器并不受限于某种具体的网络协议,可以适应任意一种网络协议。
网络处理器类似于通用处理器,硬件架构保持固定,由软件决定网络处理器如何处理数据包。
相比通用可编程数据平面,网络处理器的设计与实现已经非常成熟,有很多完善的设计工具和案例可供参考。
任何技术的发展都不是一帆风顺的,也不可能一蹴而就。作为一种理想的SDN数据平面,通用可编程数据平面还不够完善,还需要在不断的尝试中摸索前进。
从零开始实践
Mininet
Mininetl是SDN实践必不可少的工具之一,可用于快速构建SDN网络。
Mininet简介
Mininet是由斯坦福大学的Nick McKeown教授(Nick教授是SDN和OpenFlow的创始人之一,是ONLAB组织的成员,也是现在P4语言的推动者)研究团队开发的开源软件,是一个基于Linux Container虚拟化技术的轻量级网络模拟器。
Mininet 可以在普通个人电脑的操作系统上模拟出包括交换机、主机和控制器等软件定义网络的节点,从而满足网络研究人员对搭建网络环境的需求。
Mininet功能强大,支持学术研究、原型验证、调试和测试等多种网络研究需求,其支持的功能可细分如下:
- 提供用于OpenFlow应用测试的简单、免费网络实验平台。
- 支持多用户独立地在同–张拓扑。上进行并发操作。
- 支持系统级别的可重复、可封装的回归测试。
- 无须启动物理网络就可以支持复杂拓扑的测试。
- 提供用于网络调试和运行测试的CLI,支持拓扑相关和OpenFlow相关命令。
- 支持任意拓扑,包括设置拓扑的基本参数,比如网络带宽等。
- 提供Python API用于拓展功能等编程,实现网络创新。
Mininet采用Python语言编写,源码通俗易懂,整体代码也只有3千多行。
Mininet的交换节点支持Open vSwitch等多种软件交换机,可在启动拓扑时指定交换节点的类型。
此外,为了方便测试,Mininet 还支持安装控制器NOX、POX和Ryu等,也支持安装交换机性能测试软件OFlops及OpenFlow的WireShark插件等其他软件。
除了以上提到的安装特性,可以在安装Mininet时查看帮助信息获取更多的安装信息。
Mininet 也支持在虚拟主机中启动Iperf等发包工具。如果希望Mininet支持更多的功能,也可以对Mininet进行扩展。
Open vSwitch
Open vSwitch简介
OVS是当下最流行的开源软件交换机,其代码遵循Apache2.0许可证。
OVS 支持通过软件编程实现网络的自动部署,还支持标准的网络协议和网络管理接口,如NetFlow、sFlow、IPFIX、RSPAN、 CLI、 LACP、 802.1ag。
此外, OVS还是类似于VMware’s vSwitch和思科的Nexus 1000V那样的软件实现的分布式交换机。
OVS还支持Xen/XenServer、KVM和VirtualBox等多种Linux虚拟化技术。
自OVS诞生以来,其版本不断迭代更新,支持的特性也越来越多,目前最新的LTs(Long Term Support)版本已经更新至2.5.0。最新版本支持Rapid Spanning Tree Protocol (IEEE 802.1D-2004), IGMP版本1、版本3和版本4,OpenFlow1.4 协议,VXLAN,GRE,LACP和DPDK等。
Open vSwitch架构
OVS架构如图5-5 所示,其架构由OVS内核模块的datapath、用户空间的vswitchd和ovsdb组成。
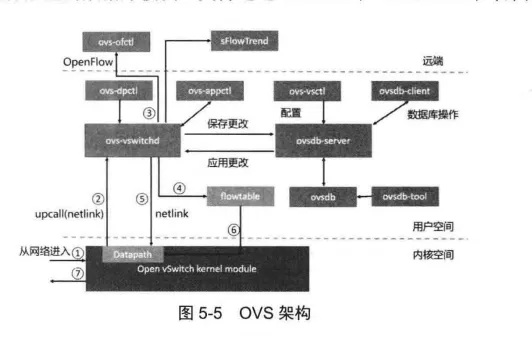
内核的datapath负责数据的转发,其从网卡中读取数据,并快速匹配流表中的流表项,成功则直接转发,失败则上交给vswitchd处理。datapath 模块可以通过ovs-dpctl命令来配置和操作。
vswitchd是OVS的核心模块,负责与OpenFlow控制器和其他第三方软件通信,是OVS的主程序,支持通过ovs-ofctl来配置。
ovsdb模块则是用于存储OVS具体配置的数据库模块,支持通过ovs-vsctl和ovsdb-tool命令来配置。
OVS的数据包匹配分为Fast Path (快速通道)和Slow Path (慢通道)两种。
快速通道是指数据包进入OVS之后,由datapath模块处理,直接匹配内核的缓存流表项,匹配成功则直接转发的通道。因为直接在内核态处理,无须up call到上层,所以处理速度快,称之为快速通道。
反之,在datapath匹配失败之后将数据upcall到ovs-vswitchd模块,ovs-vswitchd 模块处理之后再通过netlink 将数据交给datapath 转发的通道称之为慢通道。
ovs-vswitchd 模块的处理流程为:
接到数据包后,匹配用户态的流表项,成功则交由datapath 转发,并将对应流表项重新写入内核中的缓存流表中,从而让数据流的后续数据包得以快速转发。
如果匹配失败,则根据OpenFlow版本的规范处理,比如上报给控制器或丢弃。
如果控制器处理成功则下发Flow_mod报文,OVS将对应Flow_mod报文中的流表项写入到用户态的流表中,用于后续匹配。
内核态的缓存流表空间很小,所以更新速度很快,存放的都是最新命中、最高命中率的流表项。
用户态流表和内核态流表的设计与计算机系统中的内存和缓存设计类似,高速缓存、速度快,存放高命中的内容,而内存中存放普通的内容。
根据命中率来实现缓存中数据的更新,以此来提高整体性能和资源的利用率。所以内核态缓存流表的设计可以提高整体数据包处理的真实性能。
Ryu
Ryu简介
Ryu是由日本NTT公司在2012年推出的开源SDN控制器。
Ryu 基于Python 语言开发,其代码风格优秀,模块清晰,可拓展性很强。此外,Ryu使用了OpenStack 的Oslo 库,整体代码风格迎合OpenStack,并开发了OpenStack的插件,支持和OpenStack的整合部署。
作为一个开源控制器,Ryu开源社区非常活跃,版本迭代也十分快速,是一个充满活力的SDN框架。Ryu自推出以来,不断迭代新版本,目前已经迭代到4.7版。
Ryu作为一个简单易用的轻量级SDN控制器,得到了SDN初学者的青睐,成为目前主流的控制器之一。
此外,Ryu 也得到了一些交换机厂商的认可,比如被Pica8采用作为交换机的预安装控制器。
Ryu架构
Ryu代码模块化风格明显,其整体架构与其他SDN控制器架构类似,大致可以分为控制层和应用层,其架构如图5-11 所示。
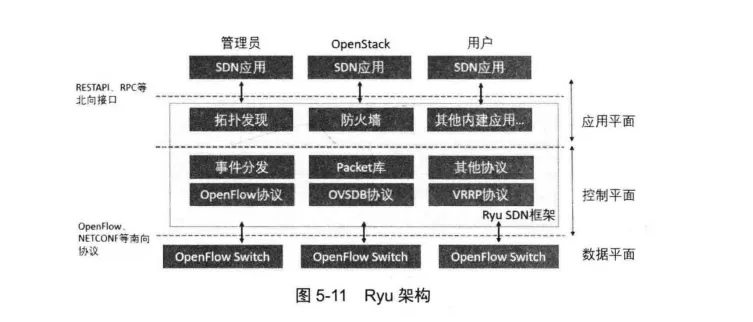
控制层主要包含协议解析、事件系统、基本的网络报文库和内建应用等组件,
而应用层则是利用控制层提供的API来编写的网络应用及和其他系统协同工作的组件和模块。
Ryu 通过南向接口与数据平面的交换机进行通信,通过北向接口完成应用层和控制层的通信。当转发设备与Ryu建立连接之后,则通过对应的南向协议如OpenFlow协议来传递信息。
面向北向,Ryu 提供了REST API和RPC等接口,允许外界的进程与Ryu进行通信。
Ryu启动时,首先需要读取输入的预启动应用及其依赖的应用模块,并将这些应用模块放在启动队列中,然后按序启动。
如果启动时没有指定任何应用的话,将会启动ofp_handler 应用。
ofp_ handler 模块是处理OpenFlow的主要模块,主要负责交换机管理和基础的OpenFlow事件处理。
该模块启动时,会实例化cortroller/cortroller.py应用中的OpenFlow Controller 实例。
OpenFlow Controller 对象实例是一个socket服务端程序,负责交换机的通信连接请求,并与交换机进行通信,是Ryu控制器最底层的模块之一。
每个交换机与控制器相连之后都会在该模块中初始化一个Datapath对象来对描述交换机。
Datapath对象完成了数据的收发工作,包括从字节流解析OpenFlow报文、OpenFlow事件的生成、OpenFlow消息的序列化及发送工作。
此外,在启动Ryu时,也启动了App Manager实例,该实例负责应用的注册、事件的注册和监听等内容,是Ryu的信息管理中心模块。
网络虚拟化平台实践
OpenVirteX简介
OpenVirteX (以下简称OVX)可以实现多租户的网络虚拟化。OVX是介于租户控制器和交换机之间的转换平台,如图5-14所示。
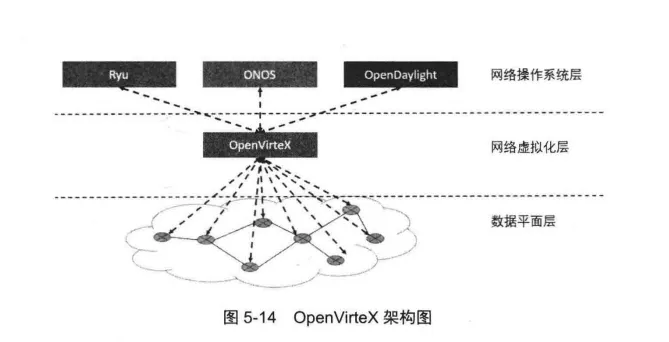
面对租户,OVX就是一个数据平面网络,而面对交换机,OVX就是控制器。
对于租户而言,仅需要在OVX上完成注册,申请资源等操作就可以使用和管理从物理网络虚拟出的一张虚拟网络。
OVX根据租户的需求,将租户的虚拟网络拓扑映射到具体的物理拓扑上,租户只能看到租户虚拟网络,无法感知真实物理拓扑,也不需要关心真实拓扑。
这种实现方式一方面提供了面向租户的网络,另一方面对用户屏蔽底层物理网络也将提高网络安全性。
OVX提供的网络虚拟化服务允许多租户共享同一网络基础设施,同时允许租户对其虚拟网络进行自主控制。
OVX为租户提供了完整的虚拟拓扑和任意的网络地址空间,不仅允许租户自定义网络拓扑,也允许租户使用任意的网络地址。
OpenVirteX架构
OVX介于租户控制器和底层网络之间,其架构如图5-15 所示。0VX内部分为三大部分:
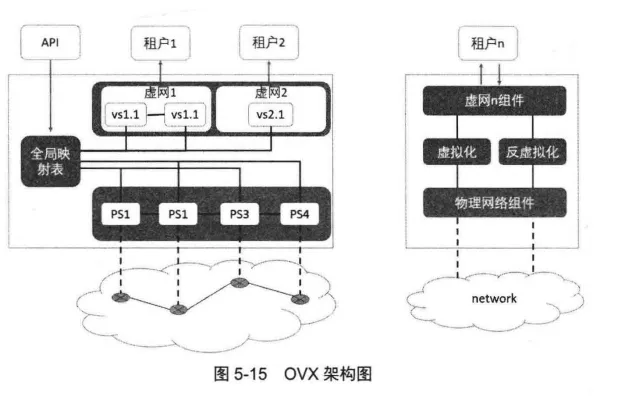
面向底层物理网络的物理网络描述部分、面向租户控制器的虛拟网络服务部分和介于这两者之间的全局映射表部分。
面向物理网络的物理网络描述部分和普通控制器的功能并无差异,负责收集网络拓扑等信息,完成物理网络的逻辑描述工作。
为了实现向租户提供虚拟网络服务,需要模拟出虚拟交换机、虛拟链路等虚拟网络元件,这部分功能由面向租户的虚拟网络描述部分完成。
为实现虚拟网络和物理网络资源的映射,还需要保存全局的映射关系表。该表由OVX核心维护,可通过API来提交映射规则,也支持自动的映射规则。
基于资源映射关系,OVX作为中间代理将底层交换机的数据转发给指定的控制器,也负责将租户的消息翻译转发给指定的交换机。
所以,上行的处理流程称之为虚拟化(Virtualize),而下行的处理流程称之为反虚拟化(Devirtualize)。
OVX通过修改、重写OpenFlow报文来实现租户控制器与租户租用的物理网元之间的通信。
这种方法使得OVX具有以下两种能力:
- OVX提供支持OpenFlow的可编程虚拟网络,从而使得租户可以指定租户控制器来控制网络。
- OVX支持透明代理。对于租户而言,OVX是底层网络,而对于底层网络而言,OVX是控制器,租户和底层网络都无须做任何修改,无法感知OVX的存在。
其他工具
Cbench
SDN控制平面的性能直接影响到SDN网络的整体性能,所以控制平面的性能非常重要。如何选择性能更好的控制器,也是在采用SDN方案时首先需要解决的问题。
Cbench是一款用于测试OpenFlow控制器性能的开源软件。
Cbench可以模拟一系列软件交换机,然后向控制器发送OFP Packet In 消息,从而测试控制器处理Packet-in消息的吞吐量和时延,进而评价控制器的性能。
OFTest
OFTest是一个基于Python 语言开发的OpenFlow交换机测试框架和测试案例集合,其架构如图5-27所示。OFTest完成了一系列的单元测试,目前支持OpenFlow1.0和1.1版本的测试,1.2版本的测试正在开发中。
使用OFTest 可以测试OpenFlow设备对各个OpenFlow报文的处理机制是否完备正确,测试也包括报文中的所有动作。
Wireshark
Wireshark(前称Ethereal)是一个开源免费的网络数据包分析软件。
网络数据包分析软件的功能是截取网络数据包,并尽可能显示出最详细的网络数据包信息。
Wireshark 是目前全世界应用最广泛的网络数据包分析软件之一。
发包工具
lperf
Iperf是一个数据包生成工具,可以向网络中打入TCP/SCTP、UDP等数据流量去测试网络带宽的工具。
Iperf支持跨平台使用、支持多线程,还可指定发送数据的速率、周期等特性,可以用于带宽和硬盘读写速度的测试。
Mininet工具安装时自动安装了Iperf,可以在Mininet中直接使用Iperf。
Iperf 支持通过下载官方的文件进行安装,也支持apt-get安装。
Scapy
Scapy是一款强大的发包工具,可以构建多种协议的数据包。支持数据包的发送和接收、抓取和回复等功能。可以轻松完成端口扫描、故障定位、探测、单元测试、网络攻击和网络发现等工作。
在实验中,有时需要向目标主机发送特定的数据包,就可以使用Scapy进行封装和发送。
小故事
我是一个SDN控制器
“醒醒!”朦胧中有一个人叫醒了我。
“跟我走!”那个身穿Linux制服,胖得像企鹅一样的大叔拉着我就走。
“你谁啊?去哪里?”我惊恐地问,完全不知道到底发生了什么。
“我是操作系统,负责给你安排工作。你是一个SDN控制器,是Ryu族人,就给你分配代号9527吧。”那大叔显得有些不耐烦地回答。
“看到没有,前面办公楼里的6633房间就是你的办公室,你的工作就是处理信件和包裹,门房的卡大爷负责收发信件,你记得找他取信就可以了,不然过期他会丢掉的。”大叔边走边说,一转眼已经到了门口。门房果然有一位大爷,正在忙着处理堆积如山的包裹,胸口的工作证沾了好多灰尘,不过隐隐约约还是可以辨出“网卡”两个字。
但我依然不知道我具体要做什么,所以忍不住又问:“操作系统大哥,我来这里干什么啊?”
“你这么叫不累?叫我Linux就好了。你是新来的员工,要做什么可以看你胸前的说明书。?
我低头一看,我的天啊!我贴着这么大的说明书,和路过的5个美女打了招呼,她们还对我笑了。我拿下说明书,发现上面赫然写着“READ ME",怪不得刚才有个小孩一直跟着我,还碎碎念着什么SDN,我还以为他只是脑子发育有些迟缓。羞愧之余,我慢慢往下读。
原来,我被任命为因特奈特国金银岛的快递主管。因特奈特国很贫穷,民众普遍文化水平不高,识字的人并不多。为了实现远距离的通信和物流,快递业务急需文化水平高的员工。所以,快递员们都是从培训机构里面毕业出来的,都是读书人。
培训机构的培训项目五花八门,有数据链路层语言和网络层语言等多种项目。但是学习语言需要天赋,有的人智商高,CPU更强大,能理解和运用三层甚至更高层级语言的语法,能找到更好的工作, 一般都在关键物流节点上工作。而那些只会普通二层语言的快递员,也就勉勉强强能在村里当一个邮递员,业务能力差强人意。
培训学院课程特色十分鲜明,有时不同机构对同一件货物的处理流程截然不同,所以不同机构的快递员之间很难合作。为了和其他学院毕业生合作,学生要学好几套技能,所以学费也相应增加了。但掌握多项技能的毕业生,可以找到很好的工作。但对于快递公司而言,人力成本就水涨船高了。快递公司希望所有培训机构的课程都一样,或者他们能快速接受入职培训重新学习,这样就可以节省很多成本了。
在工作中,快递员学员们都各自为战,并不清楚整体的物流情况,所以就有可能出现这样的情况:发货地点和收货地点之间有多条物流通道,但是物流都拥挤在-条通道上,处理不过来的包裹不断被丢弃,但有的通道却门可罗雀,快递员在岗位上打盹,导致整体资源的利用率很低。而且随着因特奈特国推行改革开放政策,经济快速发展,信息和物资开始大量流通,也对物流系统提出了更高的要求。
后来,遥远的地方传来了“深度改革”的呼声,他们对快递公司进行了改革,聘请了一个特别聪明的人担任快递业务主管来统一管理物流业务。而快递员的学习标准也都统一了,他们不需要学习多种语言,只需要识字,能按照工作手册转发货物就行。遇到不知道该怎么处理的货物时,快递员们只需要按照语法书的规则把问题提交给快递主管快递主管就会利用他的聪明才智指导快递员处理包裹,给快递员一条转发类似货物的指令,这样,快递员就可以查手册直接处理类似的货物,而不必再问主管。听说那个地方的快递主管都是牛仔,很忙的。
再后来,改革的春风吹到了因特奈特国,所以,我就成了因特奈特国金银岛的第一任快递主管。
“你不识字?读这么久?”Linux -脸鄙视地看了我一眼。
“赶紧开始工作,不然我就把房间没收了,送你去垃圾场处理掉!”Linux突然面露杀气,吓得我三步 并作两步跑进了6633房间,关上房门。
还没等我观察房间内部的摆设,门被敲开了,进来了几个穿着工服的人。
“领导好!我们是帮您完成工作的协程。”那个大众脸的人,一脸憨厚地开始自我介绍,“我是帮您取快递的小曲,她是帮您处理二层包裹的阿楚,他是帮您检查包裹安全的大健。”
我定睛一看,小曲还好,长相正常,3分吧;阿楚倒是还挺可爱的;但拿着盾和大宝剑的大健实在让气氛有些尴尬。
“那开始干活吧。”我假装经常当领导的样子,不动声色地抛下一句,然后拿起桌子上的工作手册独自读了起来,以深藏功与名。
小曲的工作比较简单,只是不断地检查房门口有没有包裹。突然,他兴高采烈地抱进来一堆信件,放在我桌子上之后,像发现新大陆一样兴奋地说:“还有其他信,您等着。
打开信件一看才发现,原来都是一些来自快递员们的Hello信件,看来他们开始工作了。Hello信件的内容很简单,无非就是和我商量一些要采用哪个版本的语法进行通信。我给他们发了Hello 回信,然后写了一封要求他们发简历的Feature_request信。作为领导,了解员工能力是很有必要的。
很快,小曲又抱着一堆新的信件进来了。这次的信有点厚,打开才发现是快递员们的Features_reply, 这些信里面有他们的简历,可以知道他们都会些什么技能。我查了一下工作手册,并没有什么要特殊设置的,就按照标准的流程,给他们回复了标准的配置信。
一转眼,小曲又大汗淋淋地扛着一个大包裹进来了。我忙不迭地打开查看,这次是一个Packet_in 包裹。“阿楚,赶紧处理一下。” 我冲一直在边上无聊抠脚的阿楚喊。
阿楚驾轻就熟地把包裹打开,把上面的信息记录到小本子上,比如包裹是哪个快递员送过来,从他的哪一个快递窗口进来的,还有一些包裹里的具体内容。阿楚也是上过小学的人,在培训学校里学过二层语言。她是这里唯一的实习生。
“我不知道这个怎么处理,没有见过这种包裹,在我的小本本上没有记录,就让他给所有出口都发一份吧。”阿楚面露难色地告诉我。我最开始是拒绝的,但又只能无奈接受。“那就这样吧。”
很快,其他快递员也把这个包裹的处理请求上报给我了,但阿楚依然不知道怎么办,只能继续泛洪发送。
可喜的是,阿楚的小本子上很快就记录了很多记录。我仔细一看,小姑娘还挺聪明,还学会数据结构了。她画了个表格,每条数据项有三列数据:快递员的工作证号(dpid)、从哪一个快递窗口送到快递员手里的和包裹主人的地址。
“这个包裹我知道怎么处理!”阿楚兴奋地跳了起来,面色潮红。根据之前的记录,阿楚知道寄给这个“66: 66: 66: 66; 66: 66”的包裹是应该要从1号快递员的快递窗口3发送出去的。她赶忙写了一封Flow_mod挂号信,信里告诉快递员关于这个有特别多6的客户的包裹都往3端口发。
“啊,糟了!我忘记给他发一个Packet_out信了! Packet_in消息里有提到buffer_id是NO_BUFFER的。”阿楚还没有坐稳就惊呼了一句。她赶紧写了一封Packet_out 信,里面提到了要把Packet_ out 中的包裹发到3端口,然后把信贴到包裹上,交给了小曲。
工作就这么有条不紊地进行着,大家都低头忙着自己的事情。仿佛时间并没有流动,只是在不断地重复,没有什么波澜。每次包裹到的时候,大健也会机械地抬头看一眼是不是给自己的。他总是恶狠狠地盯着盾牌上记录的坏人名字和处理规则,咬牙切齿的样子让气氛格外尴尬。无聊地时候,大健也喜欢在空中比划着什么。听阿楚提起过,大健好像是情意绵绵剑的传人,只是一直加班,没时间找女朋友,所以一直找不到搭档练剑。
“终于等到你!还好我没放弃!"大健两眼放光地盯着手中的信件。原来大健收到了程序员写给他的一封规则信,信里提到要把IP是192.168.8.24 的包裹全部丢掉。大健面露杀气地举起手中的大宝剑,在盾上深深地刻下了这行规则。然后他立刻写了几封Flow_mod信,把这个丢包规则发送给那些相关的快递员。作为一名安检员,大健始终保持着警惕,尽职尽责地保护着金银岛的物流安全。
工作的日子总是单调的,像一次函数那样单调而笔直地前行着。大家都机械地处理着手上的业务。阿楚还是那么萌,大健还是疾恶如仇,而小曲还是像流行歌曲的高潮部分那样,不断周期性地往返着。
平静而平凡的生活终于被打破了,犹如平静的贝加尔湖面上丢进了一块石头。原因是新来的快递员的传递路线和其他快递员的传递路线形成了环路。
那一天,乌云密布,雷雨交加。快递员收到了一个新用户的包裹,他查了半天规则手册都不知道怎么处理这个新用户的包裹,只能请求我。我让阿楚处理,结果她按照自学习那一套,让大家泛洪发送,结果就产生了广播风暴。
那是黑暗的一天,我记得是星期五,我目睹过5起交通事故和3次情侣吵架,但都没有广播风暴带来的后果严重。所有环路上的快递员都不断转发着那个货物,最后竟活活累死了!在快递行业中,丢个包已经是工作事故了,而累死多名员工的事,已经不能算是事故,它是灾难!
因为这件事,差一点让我们快递部门倒闭了。还好问题发现得及时,切断了快递业务路线。处理完所有的事之后,公司开始追究责任。可怜的阿楚,就这么被开除了。到离开,她都不知道为什么会把快递员活活累死,毕她只上过小学,只知道自学习转发,并不了解这个做法在环路中可能产生致命的环路风暴。
阿楚离开后的第二天,快递系统还没有恢复运作,办公室堆积着好多事没人处理,我并没有打算处理它们,只想放空自己,从噩梦中走出来。
突然Linux敲开了我的房门,还带着一个漂亮的姑娘。
“9527,程序员托我给你带新人来了。”程序员发现这个惨案之后,很快让操作系统把这个新员工安排过来。
“谢谢Linux。那个,你自我介绍一下吧。”谢过操作系统大哥之后,我转头问这个很有御姐范的姑娘。
“Ryu 领导好,我叫露露,读过本科,专业是大数据处理,后来去思科学院学习了快递技术。我会收集快递员的连接信息,然后做数据分析,可以计算出最短路径来转发或者路由快递包裹,绝对不会累死人!”露露语速很快,很自信,是我喜欢的类型。
“啊,小露露很厉害啊!听你这么一说我就放心了。快上班吧,不然你没响应就会被带回去了。”我满脸堆笑地对露露说。眼前这个聪明又漂亮的员工,比那个小学生水平的不知道高到哪里去了。
露露果然雷厉风行。上班之后就周期性地让快递员们发送携带dpid和出货窗口的LLDP报给邻居。收到包裹的邻居快递员会按照规则把这个包裹上报给我。露露利用上报包裹外面的Packet_ jin 信的快递员的dpid和收货窗口及包裹中的信息,可以建立两个快递员之间的连接。然后,她把所有的连接组织起来,竟然把全局的物流拓扑图画出来了。我不由心里一惊:小露露不仅长得漂亮,还很能干啊。哦不!我怎么能这么想呢!
应该是小露露不仅能干,还长得这么漂亮呢!
正在我神游的时候,小曲不识趣地打开门,扯起嗓子热情地说:“ 露露妹妹,你的包裹”。我注意到小曲放下包裹的时候比阿楚在的时候多停留了3ms,也比之前干活更精神了。
露露很熟练地解开包裹,然后提取出里面的关键信息。“是从绿茂花园的王大爷家到大柳树村老刘婶家的包裹。绿茂花园到大柳树村需要先经过西土城站,然后去西直门站,再经过国家图书馆站,最后到万泉河站的大柳树村。”露露照着手中的Djkstra书和物流图,竟然把快递转发路径给计算出来了。
“干得好,露露,午饭加一个鸡腿!”我激动得语无伦次,却也不敢多说,怕她知道我读书少。
但是就算有最短路径转发,我还是发现快递员的工作强度差异太大。有的快递员无所事事,而其他快递员加班加点。明明有的快递员可以帮忙的,但是货物总是到不了他那里。我仔细观察了一下,终于发现了问题。露露计算的路径虽然是最短的,但是当所有货物都按照最短的路径发货的时候,可能就拥堵了,而另一条次优的路径并没有使用到。所以,我应该还需要了解物流的压力情况。怎么才能了解呢?
正在我百思不得其解的时候,年度优秀快递员张伟终于不堪重负,病倒了。他那个快递收发点的货物已经堆积如山。我查遍了所有的手册都没有办法解决,只能发出一个警告,没想到程序员很快就派来了新员工来处理这件事。
他叫夏留,听名字估计是父母喜欢夏天,希望夏天能停留,应该是一种美好的希冀,只是读音让人浮想联翩。
“我学过数据挖掘,但是没找到工作,后来去学挖掘机,但是没学成,所以就去学快递技术了。”这是我印象最深的自我介绍词。我对他毫无理由地没有好感,也许是因为他比较帅吧。
他和露露一样聪明,专门整理快递网中的物流流量信息,然后和露露合作。露露当然也去学习进修了,掌握了基于物流流量信息计算最优货物转发路径的方法。所以快递员们的负载才得到了均衡,少了许多抱怨。
但是我总觉得夏留和露露整天黏在一起不太好,年轻人在办公室还是要克制一些。传数据快一些,多一些产出,少一些对视,少一些寒暄。
生活又恢复了平静,就像经过暴风雨洗礼的早晨。每天的工作都大同小异,因为新流量不多,所以大家都不是很忙。但是夏留需要不断收取一些快递员送上来的快递收发货统计报表,露露也周期性地和所有的快递员联系着。集智慧和美丽于一身的露露是所有快递员的梦中情人。
遇到节假日的时候,大家就会忙得不可开交,有时候难免会病倒。这时候我就会特别羡慕临省新上任的ODL和ONOS。ODL家族的人声势最浩大,且多才多艺,精明能干,部门员工也很多。而ONOS也比我要先进,他们是多胞胎共同作战,不像我Ryu族人还在孤军作战。ONOS他们家有好多李生兄弟姐妹,一起管理他们省的快递物流,资源和信息都共享,每个人分别只负责区域的管理。如果其中一个兄弟生病了,可以把他的业务交给其他兄弟代理,等病好了再接着干。这样就不用担心快递主管病倒导致业务中断的事了。
不过,我听说有个叫Distance的程序员开发了Open eXchange语言,可以架设一个层级式的部门架构。有了这样的语言,我不但可以和我的族人一起工作,还可以和不同家族的人一起工作。希望改革快一些。
我坐在桌子前,一手撑着下巴,一手握着桌子上的杯子,幻想着美好的未来。耳边是露露和夏留的窃窃私语、小曲忙碌的脚步声,还有大健那频率不变的磨剑声,自然而和谐。
突然,大门被撞开了,进来了Linux和几个凶神恶煞般的人。
“大、大哥…怎么?”我吓得唰一下站起来,杯子也被碰掉,碎了一地。
“这些人都带走,那个姑娘轻点抓,挺好看的。”Linux并没有理会我,指挥小弟们把我的露露、夏留和小曲,还有一-直在角落磨剑的大健五花大绑了起来。
“我收到程序员上帝的通知,由于业务整改,你们部门的所有资源都要回收,都给我去垃圾回收站,走!”Linux露出我从未见过的凶狠眼神。我明白了,我不该对未来充满幻想,我不该有任何怨念。但是,我要做完我该做的事,我转身写了 最后一封告别信:“Ryu is going down!“”
“交给程序员,告诉他我干得很好。”我把信交给操作系统,慢慢闭上了眼睛。在去往垃圾回收站黑暗而崎岖的路上,我听到露露拼命的呼喊,还有夏留,还有…
“我想我没有做错!”想到这里,嘴角颤了一下,掠过一丝转瞬即逝的微笑。
黑暗中,我睁开眼睛,仿佛看见了未来。
我是一个SDN交换机
我叫阿飞,是大柳树村的快递小哥。阿飞是我的外号,因为我送货很快。
我做着普通的工作,拿着普通的工资,买不起房子,一直单身。但我知道,只要努力,就能出人头地。在因特奈特国,识字的人并不是很多,幸亏我还读过小学,才能成为一名光荣的快递员。很多时候,大家更喜欢叫我交换机,因为我每天都像机器一样机械地交换着包裹,日复一日,年复- -年。不过很多快递员也和我一样机械地交换包裹,但我知道:我和普通快递员不一样。
老一辈的快递员学的东西很多,包括传统的OSPF和IS-IS等语言。但是随着经济的发展,新业务不断诞生,对物流系统的挑战也越来越大,前辈们也开始应接不暇。为了应对这种挑战,物流系统的深度改革终于展开了。新生代的我们只需要学会OpenFlow语言基本就可以找到工作。学习压力是减轻不少,但是我们却需要快递主管来指挥物流的转发,才能更好地工作。
还记得我当快递员的第一天,阳光明媚,室外温度28"C。上班路上,空气中竟有种淡淡的清香,像极了我读书时女同桌阿楚的发香。她学习不太好,只学会了二层转发的知识,毕业之后就杳无音信了。要是能再见一面就好了,就算见不到,写写信也挺好的。
第一次推开办公室的木门,指尖触到还未干透的露水,还有朝阳的温度。隐隐约约,还能闻到橡树的芳香。一切都是新的,房子是新的,快递窗口是新的,快递单是新的,工作手册是新的,我是新的,生活,也是新的。
走进房间之后,我拿起桌子上的工作手册,发现里面记录着快递主管的相关信息。原来我的快递主管是Ryu族人,在城里114.255.40大街2号办公大楼的6633房间工作。工作的第一件事情就是给主管发了一封Hello信,告诉主管我学会的OpenFlow语言级别。我和主管通信的信件和包裹都是重要信息,所以一般需要由专门的快递员转发,但有时候也可以作为普通信件对待。一转眼的功夫,主管就给我回复了一封Hello 信。就这样,我们就约好了使用1.0版本的OpenFlow语言通信。没等我读完,又收到控制网络快递员铁柱大哥给我送来的信件。主管在信里让我发简历给他,好给我配置工作内容。
我赶紧从我的书包中拿出修改了250遍的简历放在features_reply 信封中,然后发给了主管。我想:第一天上班,一定要好好表现,以后才能升职加薪,迎娶白富美,走上机生巅峰。脑海里不禁浮现出我成为机生赢家的画面:那是一片充满生机的草地,我拉着美丽新娘的手,肉肉的,也暖暖的,但我却看不见她的脸。我慢慢靠近她,企图看清她的脸,似乎有些熟悉,又有些神秘。就在我马上要看清的时候,一阵敲门声把我从幻想中拉了回来。又是主管来的信。
这次是配置信。我按照配置信的内容配置完我的办公室之后,满意地坐在桌子前,傻笑着准备继续幻想。
谁知第一窗口马上就传进来一件快递,我迫不及待地查看了起来:是10.0.0.8发给10.0.0.28的快递。我翻开快递转发本子,却发现转发本子上空空荡荡,正如当时我的脑海一样,一片空白。
“怎么办?第一件快递就不会处理,太丢人了!怎么办!怎么办!”我着急地一直跺脚。突然我醒悟过来,OpenFlow 语言的规范里面提到过:如果遇到不知道怎么处理的快递就给快递主管发Packet_in 信,附带上快递包裹。
“怎么这么笨!”,把Packet_in 信和包裹送出去之后,我轻轻地抽着嘴巴自责。说时迟那时快,转眼间,快递主管的包裹又到了。那是一个Packet_ out 包裹,让我赶紧把数据包给进货窗口以外的所有发货窗口都发–份。虽然不知道为什么,但是我还是照做了。
很快,我又收到了10.0.0.8 发给10.0.0.28 的另一件快递。因为上次没记录怎么处理这种类型的包裹,所以我只能再一次请快递主管帮忙了。眨眼的功夫,主管就给我回复了一个Flow_mod信,信里提到把10.0.0.8 发给10.0.0.28 的快递都统一送到3窗口。之后,我的工作就简单了很多,不用再询问主管怎么处理这类包裹了。
初来乍到,几乎所有快递都需要主管指导才能完成转发,所以我也忙得不可开交,分身乏术。幸运的是,我很快就记录了那些快递包裹的处理动作。所以,只要不是新的包裹,我都可以自己处理。
还记得第一天下班的晚上,忙碌了一天的我又激动又难过。激动是因为我终于当上了一名光荣的快递员。在大柳树村,我可是学历最高的人,那些寄信的小姑娘都会对我笑,大妈们也会询问我有没有对象。难过是因为我几乎什么都要请教主管,自己什么都不会。
时间如白驹过隙,转眼间,我已经成为一名老司机。我学会了很多快递处理的规则,基本上都不需要请快递主管帮忙了。时光就这样静静地流淌,从我忙碌的指缝中穿过,流过堆积如山的包裹,一去不返。
在没有新货物要处理的时候,我每一天都在机械地把货物从这个窗口收进来,发到另一个窗口。偶尔转发规则过了有效时间,我就把它删了,重新请教主管大人。有时遇见了新的快递,我也会喜出望外,因为我可以和主管写信沟通,哪怕是工作上的事。有个人搭搭话,总比一个人孤独工作舒服一些。虽然经常会忙得忘记时间,但偶尔闲下来,也会觉得一个人有些寂寞。
除了寂寞以外,主管待人处事的温润如玉也是我喜欢和他写信的原因。他回信很快,而且每次看主管发来的信总有种莫名的熟悉,总感觉好像是阿楚写的,无论是字迹,还是语气。不知道阿楚现在过得怎么样,只会二层算法的她是不是找不到工作,还单身吗。
忙碌的生活就像墙上简陋的日历,除了日期不一样,其他好像都差不多。生活就这么不断地重复着,直到有一天 …
那是一个星期五,印象中,我那天最后一次看墙上的钟是下午5:47, 就快下班了。屋外乌云密布,电闪雷鸣,眼看着暴风雨就要来了。当最后一丝阳光终于被黑云吞噬,屋外开始狂风大作,雷雨交加。狂风像愤怒的狮子一般呼啸着冲向我的办公室,而那些如弹珠般的雨滴,疯狂地敲击着我的玻璃窗,似乎想要冲进来摧毁一切。
忙碌的我可管不了太多,我依然认真地转发着快递。但就在这时,我发现有一个送往33:33:00:00:00:01地址的包裹不断从3窗口进来。按照转发手册的处理规则,我把它发往第5窗口。但转眼间,它又回来了,我只能再一次把它转发出去。 我逐渐意识到它在不断重复地出现,而且我发得越快,它回来得就越快,就像我和一面墙在打排球一样。我不断往返与3窗口和5窗口之间,已经无暇顾及其他的快递。堆积在窗外的包裹被雨水打湿了,开始漂浮起来,被冲走了。渐渐的,我发现自己开始上气不接下气。我突然意识到,如果继续这样不断转发下去的话,我一定会倒下的。但是我不能停止,转发快递是快递员的职责,是快递员的使命!
我依然坚持工作,纵使步履开始缓慢,呼吸也渐渐变得急促。我觉得有点晕,感觉整个房间也开始旋转,跳跃。我闭着眼,就像进入了一个奇幻的梦境。我觉得我开始飘了起来,昏昏欲睡的双眼看见椅子也飘了起来,桌子也飘了起来,还有那些转发本子和笔,都飘了起来。屋外还是狂风大作,狂风夹裹着沉重的雨点疯狂地敲击着玻璃窗,砸出无数的水花,让我看不清窗外的景象。突然,一声炸雷,把我从梦境之中拽了出来。透过窗户,我隐约中只能看见窗外的树枝被劈断,断裂处开始着火。但很快,火就被雨水无情地浇灭了。
我还在转发那个从3端口进来的包裹,不知道为什么它到达的速度越来越快,快到我还没有发送它,另一个它又进来了。往返于3窗口和5窗口之间的我,脚底越来越轻,脑海里闪过许多儿时的画面:最后一次尿床、 隔壁小红的脸、偷老爸的那根香烟…
我突然好像失聪了似的,听不到狂风的呼啸,也听不见雨水攻击窗户的声音,世界突然变得很安静,只剩下呼吸和心跳的声音,每一次都和我的脚步一样沉重。 不知为何,脑海中闪现出阿楚的模样,还有她的发香。
“我不能倒下!”我暗示自己,我知道这疯狂出现的包裹肯定有问题,肯定有问题!
“我还没有女朋友,我一-直努力工作,我不能就这么简单地走了!”我一手扶着墙支撑着自己的身体,一手颤抖着托着快递,挣扎着把它推到第5窗口。
就在包裹马上要被送到窗口时,我滑倒了,身体重重地砸到地板上。但我已经听不见倒地的声音,只觉得房间里的光线又暗了一度,让我觉得有点困。我挣扎着在地板上蠕动,努力把货物推向第5窗口出货口。我使尽了最后一丝力气,把快递顶了出去。就在这时,一阵强光伴随着一声巨响,我又被震到了地上。
我尝试着站起来,但是四肢已经没有了感觉。冷风一次又一次地从我的脸上划过,带走仅剩的一丝温度。我感觉好冷,好冷!又是一次闪电,劈在很近的地方,我失去了知觉。
那是一个幽暗的森林,没有路,没有风,没有闪电,只有安静伫立着的树,也没有声音。茂密的树叶相互遮挡着,看不到一丝天空,幽暗中,我看见不远处的草丛里有一只美丽的鹿。身上的花纹和母亲最喜欢的衣裳上的花纹一样。它看着我,眼里都是温柔,就像母亲看我时的模样。我试图靠近,鹿却向森林深处走去,时不时还回头看我,好像在召唤我一样。我一步步靠近,却感觉不到青草的柔软,感觉不到树叶刮到手臂的疼痛,感受不到一丝痛苦。
突然,一阵电流把我从梦境中惊醒!我以为我很痛,但是我没有。我还是那个我,充满活力,我被重启了。
暴风雨过去了。透过干净透亮的窗口,可以看到温暖的阳光洒在充满生机的大地上,一切都和以前一样,只是那个被雷劈断的树枝显得格外的刺眼。
我重新开始我的工作,联系我的快递主管Ryu大人,商量通信的语言版本,这次用的是OpenFlow1.3版本的语言。Ryu主管不仅给我发了配置信,还给我发了一个miss-table的处理规则,告诉我把匹配失败的数据包交给他。
使用OpenFlow1.3语言时,我需要使用3种类型的规则小本子,分别叫FlowTable、Group Table和Meter Table。以前我的Flow Table册子就只有1本,所有货物只要查-次就可以完成处理。但是现在不- -样了,我需要查多本Flow Table的本子,才能完成一个包裹的处理。我这里目前只有2本,听说最多可以支持255本。分成多种本子是因为这样可以做聚类,节省规则数目。GroupTable本子里记录着很多处理动作的集合,大约有select、all、 indirect 和fast failover 4种。select 类型的组表能做负载均衡,all 可以做组播,indirect 可以做聚合,而fast failover可以做容灾备份。Meter Table用于计量,虽然有这个规则本子,但是一般都不用,因为太麻烦了。
除了以上的差别以外,重启之后的我和之前并没有太大区别,每天都在办公室里忙着转发快递,忙着忙着也快忘记了那个黑色星期五发生的事情。后来听说,那天是大风暴,好多同事都和我一样疯狂地在转发一个数据包,到最后竟活活累死了7个快递小哥,惨绝人寰!还好我身体好才幸免于难。原因竟然只是因为一个新人把送货渠道连成了环.路,然后把不知如何处理的数据包给泛洪了,结果就产生了包裹风暴!因为这起事故,主管办公室还换掉了一些员工。
风暴之后的工作和往常差不多,只不过主管大人每周都会询问我们的业务状况,包括每个端口收发货物的详情,还包括客户之间的快递转发详情。听说收集这个是为了让我们压力均衡一些,不至于出现员工累死的事故。一切好像都比之前要好了,但写信的人好像换了,我不太喜欢这个人,不论是笔迹,还是语气。没有了当初那种青涩的感觉,多了一些严谨,多了一些犀利,听说写信的是个美丽的姑娘。
自从主管换人之后,我再也没有收到要把包裹发送给所有窗口的要求了,每一次都是直接发送到指定窗口。其他的快递小哥都喜欢这个新来的人,把她当梦中情人,但我没有。我怀念之前的信,无论是字迹,还是语气,因为很像阿楚写的。但世界这么大,哪有这么巧的事情,是我自作多情罢了。
“她还好吗?”每个寂寞的夜晚,业务不忙的时候,我总会想起她,想象着她路过我的窗,正如当年读书的模样。但我并没有遇见她,我遇见的只是跳广场舞的大妈,还有那些艳俗的姑娘,她们只是找我取快递而已。
我做着普通的工作,拿着普通的工资,买不起房子,一直单身,我坚信,只要努力,就能出人头地。但风暴之后的我面对那些转发规则信,却再也找不到那种当初的悸动。我觉得我失去了工作的热情,我只是在工作而已,麻木而机械地工作而已。
终于有一天,我再也收不到主管给我的回信了。我不断地请求主管,但发出去的信却一封封如石沉大海。听控制网络的铁柱说,主管的房间里没人了。
无奈之下,我只能按照工作手册的指导,切换到了Standalone模式。在这个模式下,我再也不需要主管控制,我可以用二层MAC自学习算法来完成我的工作。二层算法是,和阿楚同桌的时候学的,当时我教了她24遍她才会,但是就算教会了,第二天她还是过来问我这个算法,好像永远学不会一样。但我知道,她只是假装不会,而我只是在尽力表演。
生活翻开了新的篇章,相比之前的工作,工作简单多了,也无聊多了。再也没有人和我聊天和写信。我每周都让铁柱转发给Ryu主管一封信,但是始终有去无回,至今已经18年了。
我做着普通的工作,拿着普通的工资,买不起房子,一直单身。我还惦记着那个叫阿楚的姑娘,不知道现在她是什么模样,是否还有那种发香。

Use this card to join MyBlog and participate in a pleasant discussion together .
Welcome to GoodBoyboy 's Blog,wish you a nice day .

